Contents
本記事は Codatum Agent のリリースに合わせて、業界の動向と私たちの考えをまとめたものです。
1. データ分析の世界で、今何が起きているのか
データ分析の世界でも Agent の活用が急速に進んでいます。自然言語でデータに質問し、SQL を生成し、分析レポートまで組み上げる — 多くの企業がそうした取り組みを始めています。
しかし実際に使ってみると、壁にぶつかることが少なくありません。ハルシネーション、間違ったテーブルの参照、古いロジックでの計算、文脈を無視した分析 — 的外れな答えが返ってくる問題は多岐にわたります。
"Data and analytics agents are essentially useless without the right context."
"正しいコンテキストがなければ、データエージェントは使い物にならない"
— a16z「Your Data Agents Need Context」
この問題に取り組んでいるプレイヤーは多岐にわたります。Agent の精度を上げたいクラウドベンダー(Snowflake)、Agent 時代のデータ基盤のあり方を整理したい VC(a16z)や BI(ThoughtSpot)、メタデータ管理を Agent 向けに進化させたいデータカタログ(Atlan)、モデリングと AI の接続を模索する dbt Labs — それぞれの立場から、同じ課題に向き合っています。

"Models made 'text → data' plausible. Agent context makes agentic analytics trustworthy."
"モデルは「テキストからデータへ」を可能にした。しかし Agent の分析を信頼に足るものにするのは、コンテキストだ"
— Snowflake
これは、私たち自身も社内の分析 Agent や Codatum の Agent 機能を作り、使う中で痛感してきたことです。例えば「先月の売上はいくらか」に Agent はある程度正しく答えます。しかし「なぜ下がったのか」を聞くと、的外れな分析が返ってくる。人間なら一瞬で判断できることであっても、Agent は自律的に解を求めるのが難しい時があります。
「数字が急落したら、分析の前にまずデータの欠損を確認する」
「sales_summary は旧システムのテーブル。移行後は revenue_v2 を使う」
「解約分析はまずプラン別に切る。全体の数字は実態を反映しない」
「四半期末のスパイクは会計処理のタイミング。異常ではない」
「売上の前年比較を頼まれたら、Q2 のプロダクトライン再編の影響を除いて出す。過去の分析でもそうしている」
データに関わったことがある人なら、こうした判断に覚えがあると思います。人間はこれを経験や勘で補い、"隣の席の同僚" に聞くことで乗り越えてきました。
メトリクスの定義もスキーマも正しいのに Agent が的外れな答えを返すのは、この"隣の席の同僚が持っている知識"が Agent に渡されていないためです。誰かの怠慢ではなく、そもそも書き残す場所がありませんでした。
業界が求め始めているのが 「Context Layer」 です。メトリクス定義やスキーマ情報を管理する Semantic Layer だけでなく、判断の文脈、暗黙知、分析のプレイブック、さらにはガバナンスや意思決定の経緯まで — Agent が正しく動くために必要なあらゆるコンテキストを供給する仕組みで、2025年後半から急速にプレイヤーや発信が増えています。
時期 | プレイヤー | 発信 |
2024年11月 | Anthropic | Model Context Protocol (MCP) — AI Agent が外部のデータやツールからコンテキストを取得するためのオープンプロトコル。事実上の標準として急速に普及 |
2025年8月 | Atlan | Activate 2025 Recap — データカタログからの転換を宣言。「AI パイロットの95%が失敗するのはモデルではなくコンテキストの欠如」とし、自社を「The Context Layer for AI」と再定義 |
2025年8月 | Benn Stancil | The context layer — かつて単独では定着しなかったメトリクスレイヤーの概念が、Agent 時代に「コンテキストレイヤー」として復活する可能性を論じた |
2025年12月 | dbt Labs | Bring Structured Context to Conversational Analytics — dbt Semantic Layer + MetricFlow + MCP サーバーで、AI ワークフローに構造化されたコンテキストを提供するアーキテクチャを提案 |
2025年12月 | Promethium | Context Architecture: 5 Levels of Context — コンテキストを5段階に分類。メタデータのみの精度30-40%に対し、全層実装で94-99%の精度に達すると報告 |
2025年12月 | Foundation Capital | AI's Trillion-Dollar Opportunity: Context Graphs — 意思決定の痕跡(承認チェーン、例外処理等)を構造化した「コンテキストグラフ」が次の兆ドル規模のプラットフォームになると主張 |
2026年1月 | Atlan | Context Layer vs. Semantic Layer — Semantic Layer は「この指標の意味は何か」に、Context Layer は「AI Agent がこの指標をいつ・どう使えるか」に答える、と両概念の役割分担を整理 |
2026年3月 | a16z | Your Data Agents Need Context — Data Agent の失敗原因はモデルの能力不足ではなくビジネスコンテキストの欠如。最も重要なコンテキストは暗黙的で、条件付きで、歴史的経緯に依存している |
2026年3月 | Snowflake | The Agent Context Layer — プレーンテキストのオントロジーを追加するだけで Agent の回答精度が+20%、ツール呼び出しが-39%改善したと報告 |
2026年3月 | Gartner | Top Predictions for Data and Analytics in 2026 — 2028年までに、MCP のみに依存するエージェント型アナリティクスプロジェクトの60%は、一貫した Semantic Layer なしに失敗すると予測 |
2026年4月 | Atlan | Activate 2026 — カンファレンス全体のテーマを Context Layer に据え、Context Engineering Studio 等を発表 |
2. Semantic Layer とはなんだったのか
Semantic Layer は、一言で言うとデータに対するビジネスの共通言語を定義する仕組みです。「Revenue」の計算方法を一箇所で定義しておけば、どのツールからアクセスしても同じロジックで計算される。部門ごとに「売上」の数字が食い違う、といった問題を構造的に解消しようとする試みです。1990年代の BI ツールに端を発し、2013年に Looker が LookML で宣言的なセマンティックモデリングを開拓、2022年には dbt Labs が dbt Semantic Layer を発表しました。長い歴史を持つ技術・トレンドと言えると思います。
私自身、データに関わる中で「チームによって数字が違う」「何度やっても同じ数字にならない」問題にいくども遭遇してきたので、Semantic Layer が取り組んできた課題の重要性は身をもって分かります。
メトリクス定義の統一 — 部門間の「売上」の不一致をなくしたい
Self-service BI — 非技術ユーザーがビジネス用語でデータにアクセスできるようにしたい
ガバナンス — 定義の変更管理を一元化したい
これらはデータの民主化において重要な課題であり、Semantic Layer はそれを大きく前進させてきました。
しかし、Semantic Layer が扱えるのは「定義」の世界までです。Revenue とは何か、どう計算するか — これは表現できます。一方で「この数字をどう使うか」「どういう順番で分析するか」「この状況ではどう判断するか」— こうした判断の文脈は、Semantic Layer の表現力の外にあります。
Agent 時代に入って、この問題がより鮮明になりました。データ分析の民主化が進み、勘や経験を持たないメンバーも分析に参加できる素地が整いつつあります。しかしその土台となるコンテキストが整備されていなければ、Agent も人間も同じ壁にぶつかります。結果として、精度の数字にそのまま表れています。
Promethium の調査によると、メタデータのみで Agent を動かした場合の精度は 30-40%。Semantic Layer を加えても改善はするものの、暗黙知やプレイブックを含む全てのコンテキストを実装して初めて 94-99% に達するとされています。
a16z も、メトリクス定義は陳腐化すると指摘しています。新しいプロダクトラインが追加されても定義が更新されない。先ほど挙げたような判断の文脈 — 分析の手順、データの注意点、数字の読み方 — は、Semantic Layer では扱えない領域です。
Semantic Layer は重要な基盤です。しかし Agent が必要としているのは、その先にある"隣の席の同僚の知識"なのだと感じています。
3. Context Layer とは
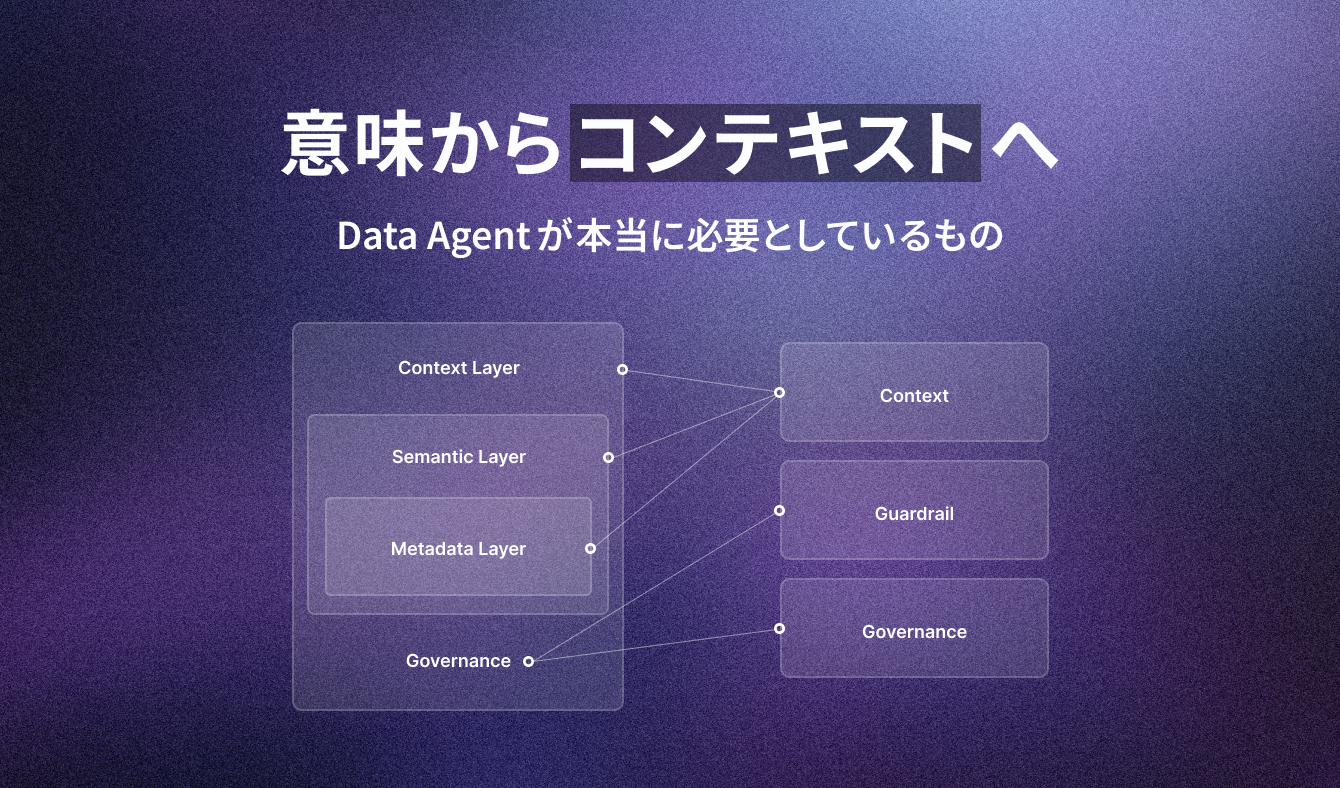
Context Layer のスコープは、多くの人が想像するよりも広いかもしれません。a16z の表現を借りれば、Semantic Layer の superset — Semantic Layer を置き換えるのではなく、それを含む上位概念としています。
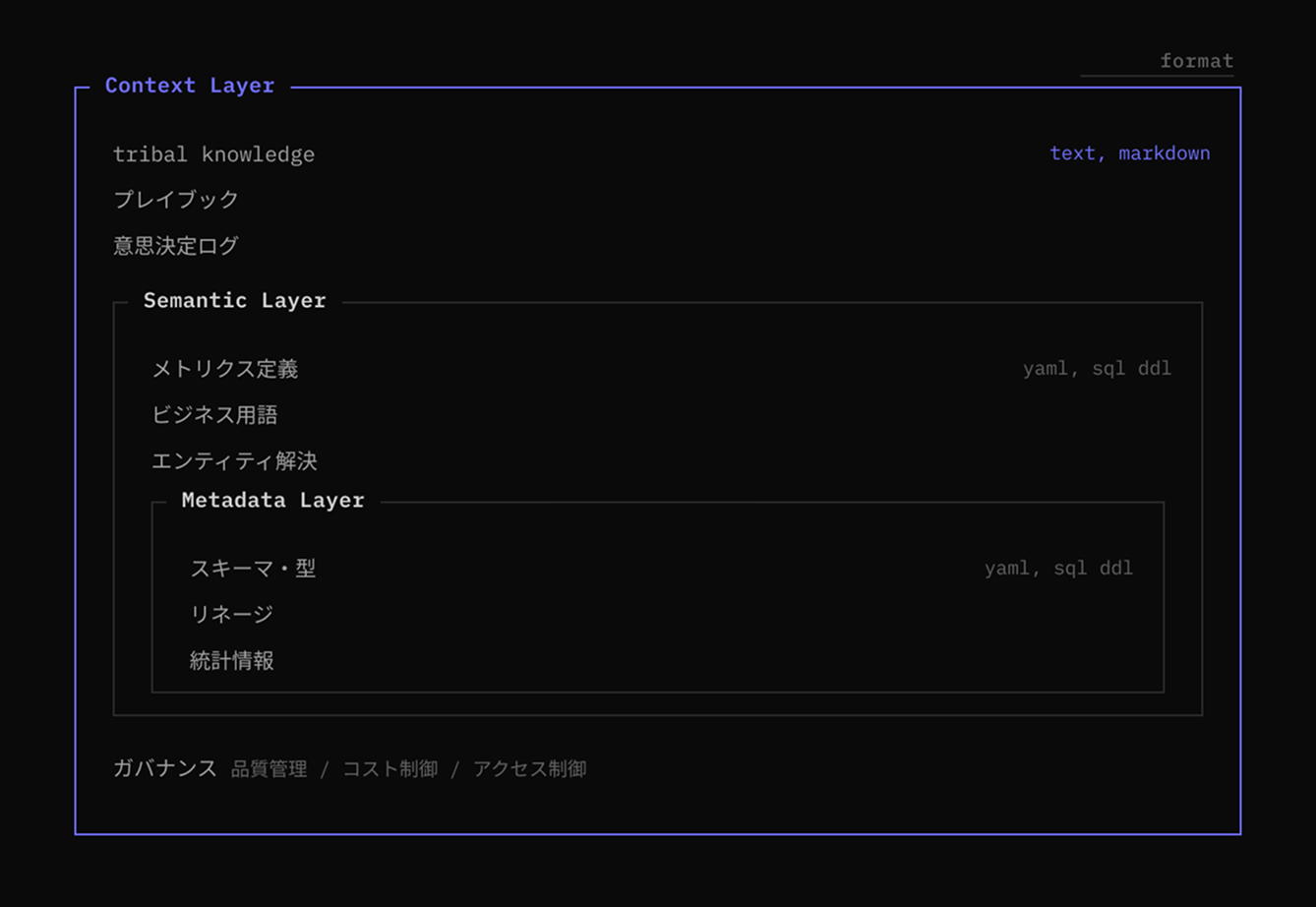
Metadata Layer(スキーマ・型・リネージ)の上に Semantic Layer(メトリクス定義・ビジネス用語)があり、その外側に Context Layer が位置する入れ子構造です。
a16z は tribal knowledge やガバナンス指針から意思決定ロジックまでを、Snowflake は運用プレイブックやポリシー・権限から意思決定メモリまでを含めています。
スコープには共通点がありますが、各社がこの概念を同じ名前で呼んでいるわけではありません。a16z や Atlan は「Context Layer」と呼び、Snowflake は「Agent Context Layer」、Foundation Capital は「Context Graph」と呼んでいます。dbt Labs は Semantic Layer の拡張として語っています。本記事ではこれらを包括的に「Context Layer」と呼んでいますが、課題認識は収束しつつも、各社が想定するアーキテクチャはまだ分岐している段階だと感じています。
ただし、この広さゆえに実装の難しさもあります。メトリクス定義やエンティティ解決は Semantic Layer の延長として構造化できますが、tribal knowledge やプレイブックは構造化しきれない。自然言語テキストで扱うしかないのが現状のようです。
実際、Snowflake の内部実験でもプレーンテキストのオントロジーをプロンプトに注入するアプローチが取られており、コーディングエージェントの世界でも .cursorrules や CLAUDE.md といった Markdown ファイルが事実上の標準になっています。
構築方法についても各社が模索しています。a16z は自動抽出から人的補完、API 公開、自己更新までの段階的なモデルを提示しています。しかし高抽象度のコンテキストを持っているのはデータエンジニアではなくビジネスの現場です。コンテキストの持ち主(現場)と、それを構築する人(データエンジニア)が分離している — 各社の議論を見ていると、これが共通の課題として浮かび上がってきます。
4. Agent 側から見た Context Layer
Agent の側から見ると、少し景色が変わります。業界が「Context Layer」と呼んでいるものは、Agent アーキテクチャの中では単一のレイヤーではなく、複数の仕組みにまたがっています。

整理すると、業界が Context Layer に含めているものは、Agent の世界では異なる概念に分かれます。
Context — Agent に供給される情報そのもの。tribal knowledge、分析サンプル、プレイブック。Agent が「何を知っているか」
Guardrails — 入出力の検証・制約。SQL 実行前の承認、ハルシネーション検知。Agent が「何をやってはいけないか」
Governance — 組織レベルのポリシー。RBAC、権限管理、監査。Agent の外側で強制されるもの
注意すべきは、業界が「Context Layer」と呼んでいるものは、Agent の世界で言う「Context(Agent に供給する情報)」より広い概念だという点です。Guardrails や Governance まで含んでいます。
それぞれに異なるアプローチが必要です。Guardrails は技術的な仕組みで担保できます。Governance はプラットフォーム側で強制できます。しかし Agent に供給するコンテキストそのもの — チームの暗黙知や分析の文脈 — は、誰かが「構築」するだけでは足りない。ここに、私たちが独自に考えている部分があります。
5. 柔らかいコンテキストとMarkdown
先ほどの入れ子構造を、抽象度の軸で見直すと、一つのことが見えてきます。
層 | 抽象度 | 何を記述するか | 性質 |
Context | 高 | 判断・解釈・暗黙知 | 柔らかいコンテキスト(構造化しきれない) |
Semantic | 中 | データの意味 | 硬いコンテキスト(構造化できる) |
Metadata | 低 | データの構造 | 硬いコンテキスト(構造化できる) |
低〜中抽象度は「硬いコンテキスト」です。YAML や SQL DDL で定義でき、既存のツール(dbt、カタログ等)が扱えます。
一方、高抽象度のコンテキストは「柔らかい」。いわゆるハイコンテキストな知識、各企業固有のドメイン知識と言い換えてもいいかもしれません。構造化しきれないからこそ暗黙知として人の頭の中に留まっていました。
この区別は、業界が言う「superset」「スコープ拡大」の本質を明らかにすると考えています。Semantic Layer から Context Layer へのジャンプは、単に扱う情報の種類が増えたのではなく、情報の性質が変わったという方が正しいかもしれません。硬い世界から柔らかい世界へ、構造化できる世界から構造化しきれない世界へ。
柔らかいコンテキストの特徴は、構造化しきれないがゆえに、自然言語で扱うしかない点です。コーディングエージェントの世界で .cursorrules や CLAUDE.md が Markdown で書かれているのと同じ構造がここにもあります。「この切り口で見たらこう見えた」「このデータはこう読むべきだ」— そうした判断の文脈は、YAML には落とし込めません。
私自身、定義された指標をサクサク見るよりも、誰かが書いた分析サンプルやメモを見て自分の分析を組み上げるのを好みます。Semantic Layer が用意してくれる「正しい数字」に加えて、誰かが残した「こう考えた」があると、分析の自由度が広がると感じています。そしてこれは、Agent にとっても同じです。Agent が本当に必要としているコンテキストもまた、こうした柔らかい文脈 — 人間が分析の中で自然に残してきたものだと考えています。
ただし、柔らかいコンテキストには裏返しの性質があります。構造化されていないがゆえに、間違いを含みうる。構造化された世界は安全だが狭い。柔らかいコンテキストの世界は広いが間違いうる。私たちは、この間違いを修正していくコストを引き受けてでも、探索的な分析ができる自由の方に価値があると考えています。
勘違いしてはならないのは、これは Semantic Layer が不要になるという話ではないことです。メトリクスの定義が一貫していなければ、その上にどれだけ柔らかいコンテキストを積んでも土台が崩れます。Semantic Layer は依然として不可欠な基盤であり、Context Layer はそれを置き換えるものではなく、その上に積み上げるものです。
6. Codatum Agent における Context Layer
ここで初めて、私たちのプロダクト Codatum の話をさせてください。
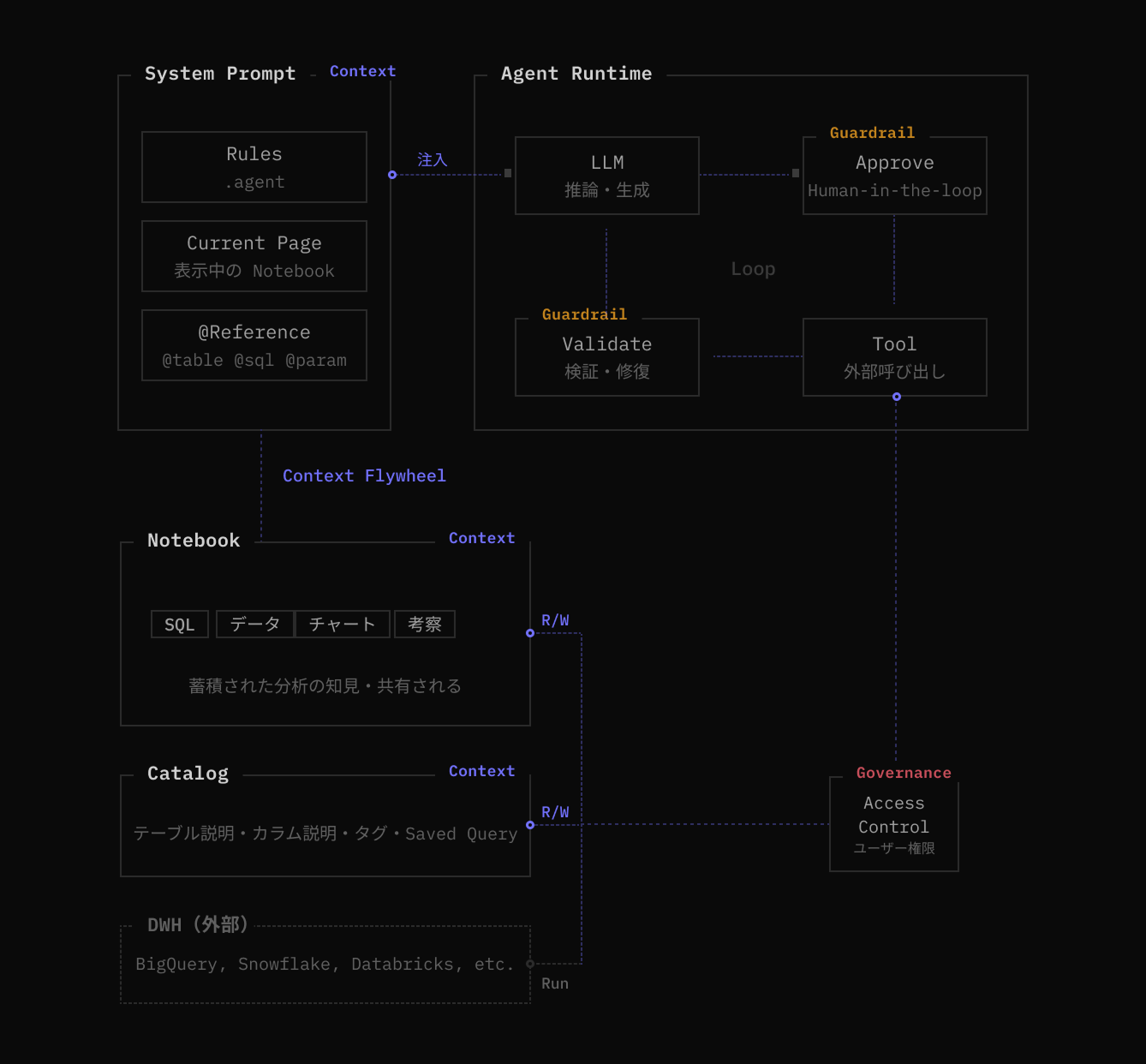
Codatum Agent は、業界が Context Layer と呼ぶ領域 — Context、Guardrails、Governance — を Agent アーキテクチャとして実現しています。Human-in-the-loop による承認、権限のフェデレーション、自動検証といった仕組みはその中に組み込まれています。
Metadata や Semantic Layer については、Catalog でテーブル説明やカラム説明、タグ、Saved Query を整備しており、dbt 等の Modeling Layer との連携も予定しています。置き換えではなく、連携です。
しかし私たちが最もこだわっているのは、柔らかいコンテキストの扱い方です。
柔らかいコンテキストが Agent にとって価値を持つには、3つの性質が必要だと考えています。中身が検証・修正できること(透明性)。分析の過程と判断が一体で残ること(パッケージ性)。そして組織に蓄積・共有されること(共有性)です。
Codatum のノートブックは、この3つをそのまま備えています。Agent が SQL を書き、実行結果が表示され、チャートが生成され、人間が考察やコメントを加える。この一連の過程が、一つのノートブックに一体で残ります。コードだから読める、検証できる、直せる。そしてノートブックだから、分析の「結果」だけでなく「過程」と「判断」が文脈ごと残る。これが、"隣の席の同僚の知識" を書き残す場所になると考えています。
7. これから
私たちの仕事はまだ途中です。足りていないものも多くあります。
Observability — Agent の実行ログを管理者やデータエンジニアから追跡可能にすること。コンテキスト改善には必須ですが、アクセスコントロールとの両立をスマートに解く必要があります
Skills・外部 MCP 連携 — Agent が使えるコンテキストの範囲を外部ツールやデータソースへ拡張すること
Slack からの呼び出し・バックグラウンド実行 — Slack から分析を依頼したり、定期的にカタログの整備や分析を自動実行させること
API・MCP 公開 — 外部からノートブックを構築・実行・検索することを可能にすることで、Cursor や Claude Code をはじめとするローカルの開発エージェント等を使うことができます
今時点では目指しているものに比べて足りないものだらけです。しかし、Context Layer の議論が業界全体で始まったこのタイミングに、私たちがこの場所にいることには意味があると感じています。"隣の席の同僚の知識"を、組織の強力な資産に変えていく。その仕組みを作り続けていこうと考えています。
8. おわりに
Codatum Agent をリリースしました!
本日、AIデータ分析エージェント『Codatum Agent』ベータ版を提供開始しました。
「Codatum Agent」は、自然言語で分析を依頼するだけで、テーブルの検索からSQL構築・実行、チャート生成までをAIが自律的に完遂する対話型データ分析エージェントです。… pic.twitter.com/ceLhAZNa2u
私たちはこの流れの中で、データ分析の本当の民主化を前に進めたいと考えています。
Codatum は無料で始められます。ぜひ試してみてください。そして、あなたの声を聞かせてください。データ基盤や Agent 活用についてお話ししたい方は、打ち合わせもお待ちしています。
参考文献
a16z — Your Data Agents Need Context (2026年3月)
Snowflake — The Agent Context Layer for Trustworthy Data Agents (2026年3月)
Atlan — Context Layer vs. Semantic Layer: Key Differences (2026年1月)
Atlan — Activate 2026 (2026年4月)
dbt Labs — Bring Structured Context to Conversational Analytics with dbt (2025年12月)
Promethium — Context Architecture: 5 Levels of Context for 94% Accuracy (2025年12月)
AtScale — The Golden Age of the Semantic Layer (2025年11月)
ThoughtSpot — Introducing the Agentic Semantic Layer
Benn Stancil — The context layer (2025年8月)
Foundation Capital — AI's Trillion-Dollar Opportunity: Context Graphs (2025年12月)
Gartner — Top Predictions for Data and Analytics in 2026 (2026年3月)
Atlan — Activate 2025 Recap (2025年8月)
Anthropic — Model Context Protocol (MCP) (2024年11月)