Contents
本記事は、2026 年に OpenAI / Meta が公開した内製データ Agent の構築事例を「現場ではどう作られているか」という観点から地図的に整理する解説記事です。Codatum 独自の主張を述べるものではなく、内製 / 既製を問わず "データ Agent を入れたい" と考えている読者向けの参照地点として書いています。
1. OpenAI / Meta が公開した内製データ Agent
2026 年に入って、OpenAI と Meta から内製データ Agent の構築事例が公開されています。
公開 | 主体 | 文書 |
2026-01-29 | OpenAI Engineering | "Inside our in-house data agent"(公式 blog) |
2026-03-30 | Analytics at Meta | "Inside Meta's home-grown AI analytics agent"(Medium) |
両者とも schema 以外の "業務文脈" をどう Agent に持たせるか という、いわゆる context engineering の設計判断を、具体的な数字と図とともに公開しています。これは個別の vendor が pitch する事例とは違い、自社で長期運用している組織の現場知見 が表に出てきた、という意味で重みがあります。
本記事ではこの 2 つの一次資料を並列に読み解き、"context engineering" は実際何を意味するのか、そして自社で類似のものを作るとき何を準備すべきかを整理します。
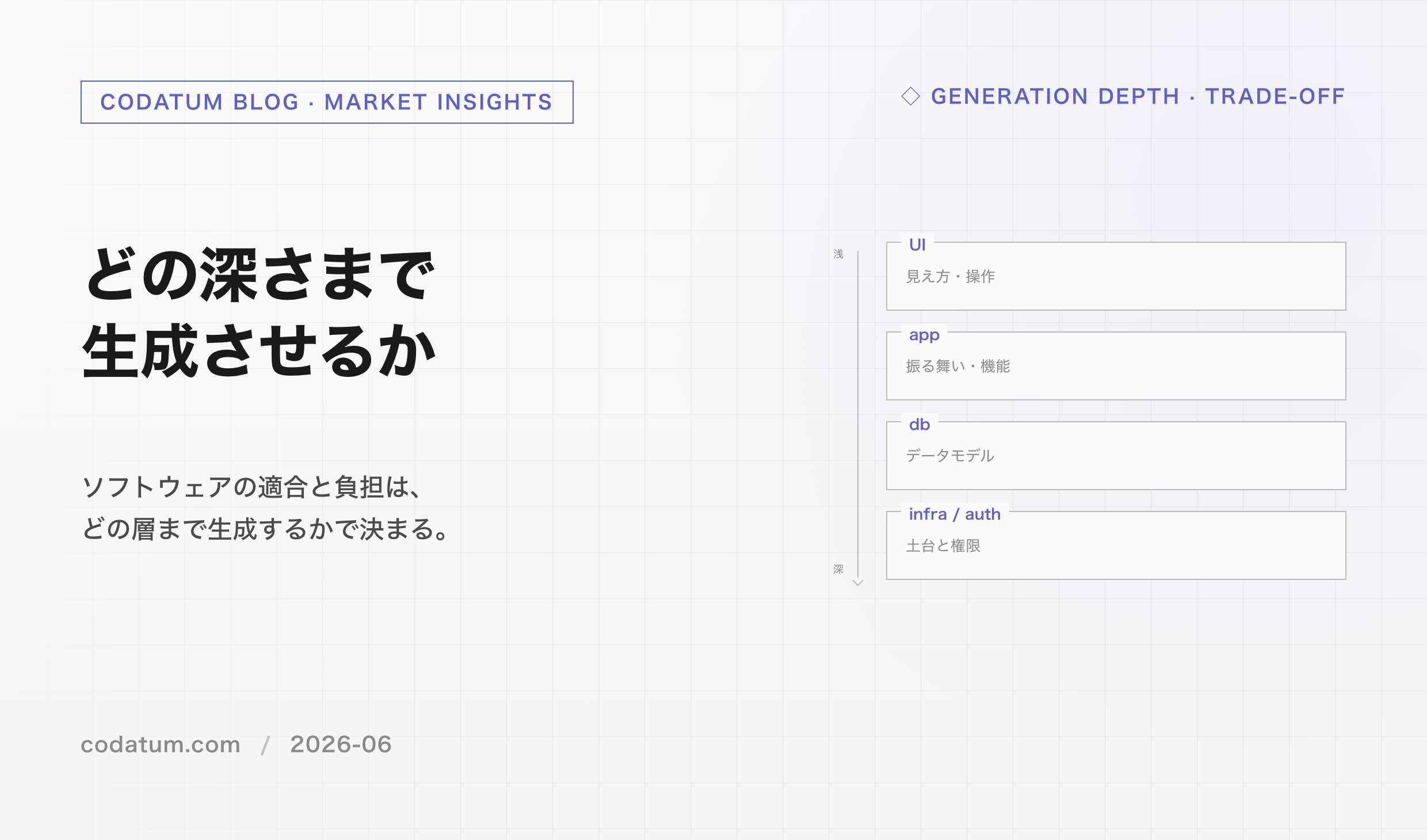
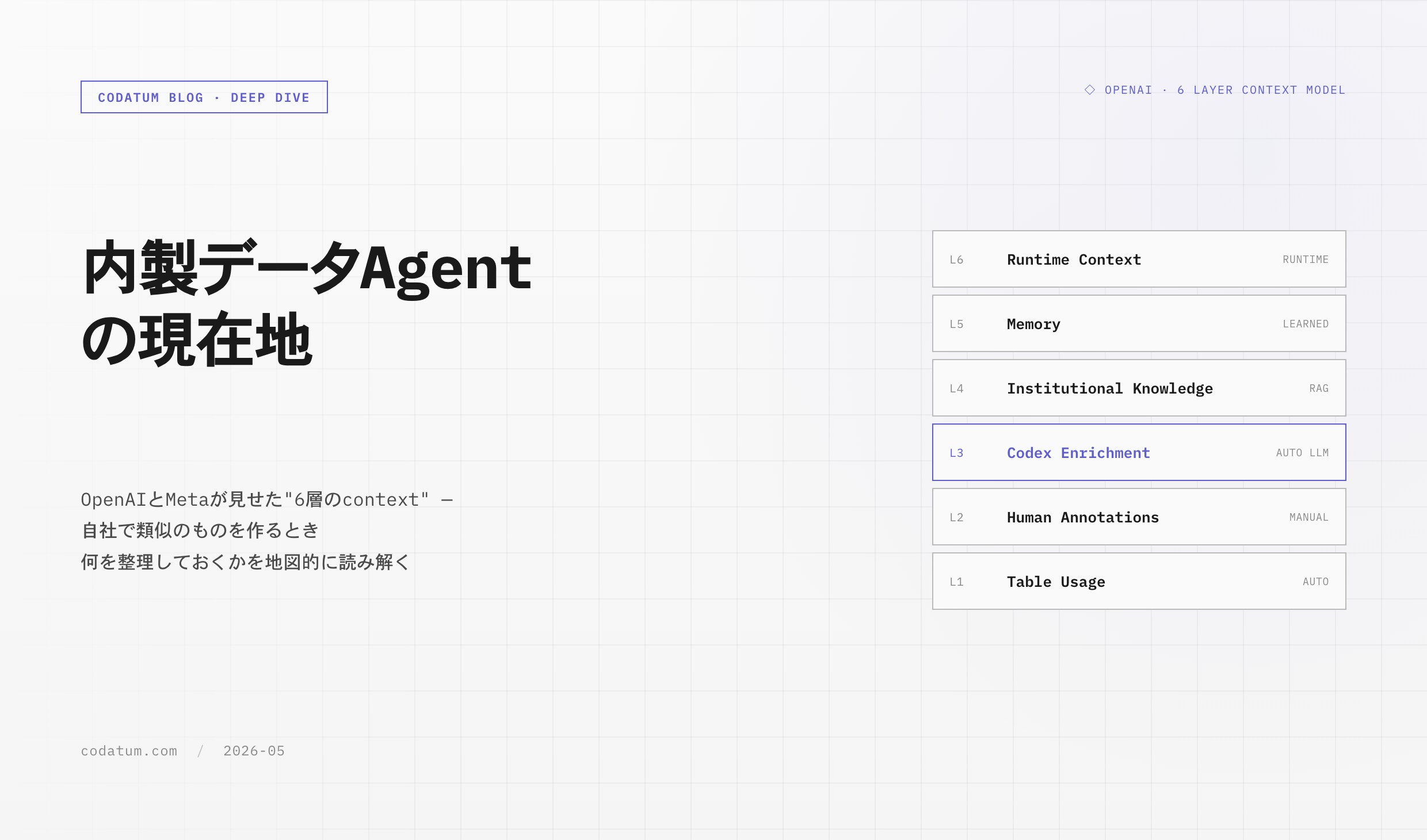
2. OpenAI の "6 層の context model"
OpenAI は内製 Agent を 6 層の context で設計していると公開しました(2026-01-29 公式 blog、Bonnie Xu / Aravind Suresh / Emma Tang)。データ規模は 3,500+ internal users / 600 PB / 70k datasets という Engineering / Product / Research 横断のスケールです。

全体像は図 1 のとおり。原文 quote と和訳を順に並べていきますが、構造だけ掴みたい読者は太字と図を辿れば筋は通ります。
層 1: Table Usage — schema metadata + lineage + 過去クエリ
"schema metadata (column names and data types) ... uses table lineage (e.g., upstream and downstream table relationships) ... Ingesting historical queries helps the agent understand how to write its own queries and which tables are typically joined together."
(schema metadata(カラム名・データ型)、lineage(上流・下流のテーブル関係)、過去クエリ — これらを取り込むことで、Agent はクエリの書き方や典型的に join されるテーブルの組み合わせを理解できる。)
schema / lineage / 過去クエリの 3 つを自動的に取得する基層です。
層 2: Human Annotations — domain expert による curation
"Curated descriptions of tables and columns provided by domain experts, capturing intent, semantics, business meaning, and known caveats that are not easily inferred from schemas or past queries."
(ドメイン専門家がテーブル・カラムに付ける説明文。intent / semantics / business meaning / 既知の注意点 — schema や過去クエリだけからは推測しにくい情報を捉える。)
手動で人がメタデータを整える層です。OpenAI 内のユーザーがテーブルの "似て非なる差" に困っている例として、こういう声が引かれています:
"We have a lot of tables that are fairly similar, and I spend tons of time trying to figure out how they're different and which to use. Some include logged-out users, some don't."
(似ているテーブルが多くて、どれが何で違ってどれを使うべきか調べるのに大量の時間を使う。logged-out ユーザーを含むものと含まないもの、とか。)
層 3: Codex Enrichment — コードベースから LLM 自動生成
"By deriving a code-level definition of a table, the agent builds a deeper understanding of what the data actually contains. ... This context is also refreshed automatically, so it stays up to date without manual maintenance."
(テーブルのコードレベルでの定義をコードから導くことで、Agent はデータの中身をより深く理解できるようになる。この context は自動更新されるため、手動メンテなしで最新状態を保てる。)
pipeline コード(Airflow / Spark など)から、Codex(OpenAI 内製の coding agent)がテーブルの コードレベルでの定義(前提条件・freshness の保証・ビジネス意図を含む)を抽出します。手動メンテ不要で自動更新される設計です。
層 4: Institutional Knowledge — Slack / GDocs / Notion を RAG
"The agent can access Slack, Google Docs, and Notion, which capture critical company context such as launches, reliability incidents, internal codenames and tools, and the canonical definitions and computation logic for key metrics."
(Agent は Slack / Google Docs / Notion にアクセスできる。launch / 信頼性 incident / 社内コードネーム・ツール / 主要メトリックの正式定義と計算ロジック、といった重要な企業 context を取得する経路。)
社内ドキュメントを 取り込み → embedding 化 → 取り出し のパイプラインで扱い、アクセス権限を保ったまま実行時に参照する仕組みです。
層 5: Memory — 会話の訂正を蓄積
"The goal of memory is to retain and reuse non-obvious corrections, filters, and constraints that are critical for data correctness but difficult to infer from the other layers alone."
(memory の目的は、データの正しさに critical だが他の層からは推測しにくい、自明でない訂正・フィルタ・制約を保存して再利用すること。)
global / personal の 2 段スコープで、ユーザーが訂正した内容を覚えて次回から使います。
層 6: Runtime Context — Agent が実行時に直接叩く
"When no prior context exists for a table or when existing information is stale, the agent can issue live queries to the data warehouse to inspect and query the table directly, which allows it to validate schemas, understand the data in real-time, and respond accordingly."
(事前 context がない、または既存情報が古いテーブルに対して、Agent は warehouse に直接クエリを投げてテーブルを確認・参照できる。schema の検証、データの実時間での把握、それに応じた応答が可能になる。)
事前に集約された context(層 1-4)に無い、または古くなったテーブルに対して、Agent が実行時に warehouse へ直接クエリを投げて schema を確認し、中身を見にいきます。さらに warehouse 以外のデータ基盤 — 原文では "metadata service, Airflow, Spark" と書かれている — にも実行時にアクセスして広い文脈を取りに行きます。L1-5 と違い、catalog 未同期 / pipeline 未反映の領域へ Agent が能動的に踏み込む層 です。
この 6 層は同じ経路で運用されているわけではありません。
層 1〜3(Table Usage / Human Annotations / Codex Enrichment) — daily offline pipeline で集約し、embedding 化して RAG で取り出す
層 4(Slack / GDocs / Notion) — 別の取り込みパイプラインで、アクセス権限を保ったまま embedding 化と取り出し
層 5(Memory) — 会話のなかで逐次保存
層 6(Runtime) — Agent が実行時に warehouse / データ基盤を直接叩く
経路は 2 つに分かれていて、「事前に集約した context を取り出す経路」と「実行時に取りに行く経路」が混在する 多経路設計 になっています。
OpenAI 自身がこの設計判断をこう要約しています:
"Schemas and query history describe a table's shape and usage, but its true meaning lives in the code that produces it. Pipeline logic captures assumptions, freshness guarantees, and business intent that never surface in SQL or metadata."
(schema とクエリ履歴はテーブルの形と使われ方を記述するが、本当の意味はそれを生み出すコードに宿る。pipeline ロジックは、SQL や metadata には現れない前提条件・freshness 保証・ビジネス意図を捉えている。)
schema だけでは語れない部分 を、コード(層 3)・人間(層 2)・社内ドキュメント(層 4)・記憶(層 5)で補う、という多層防御の構造になっています。
3. Meta の "88% は 90 日内テーブル"
Meta も同時期(2026-03-30)に Analytics at Meta 名義で Medium に公開しました。彼らの設計判断はもう少し観察ベースで、印象的なのは次の数字です:
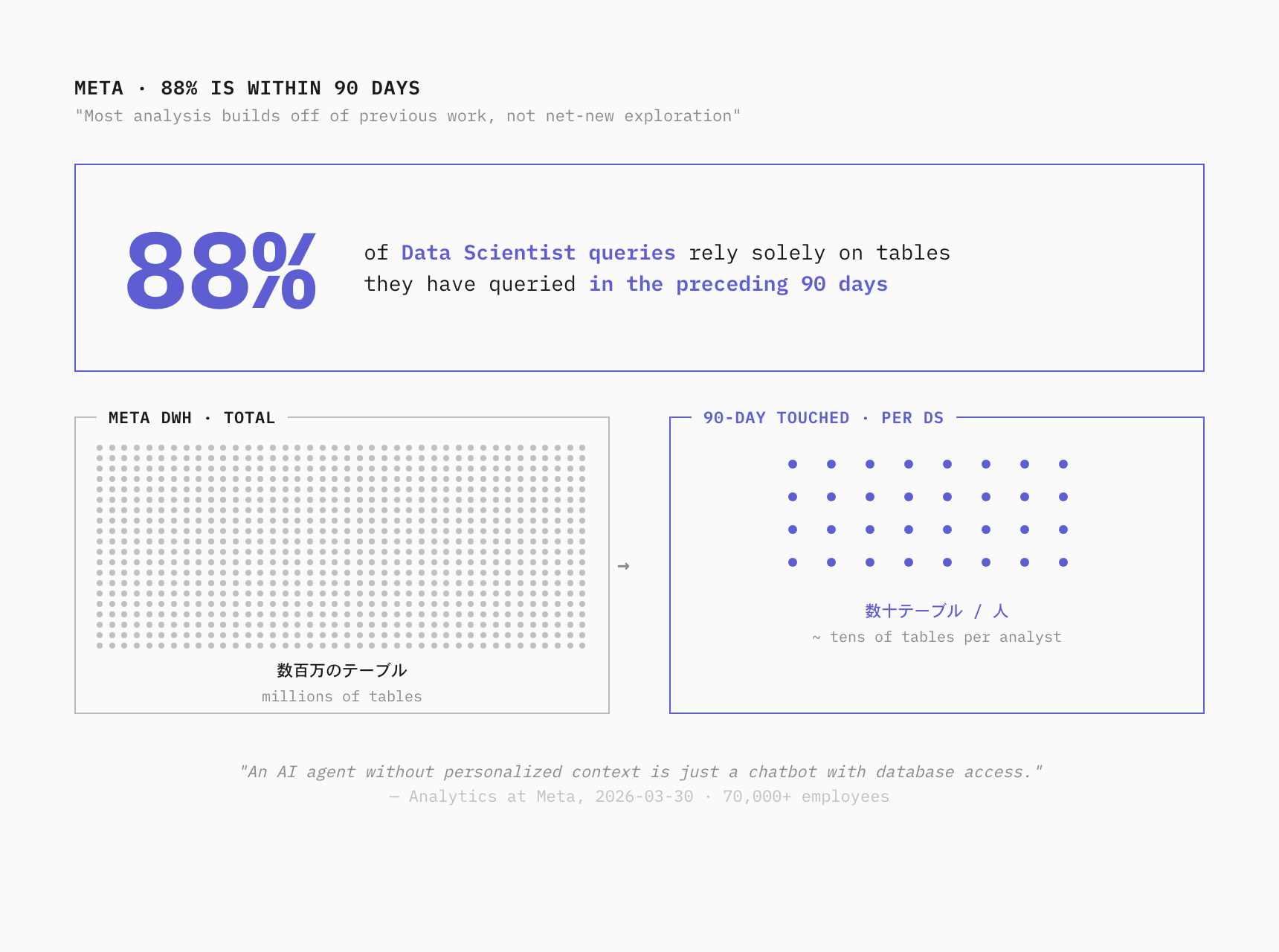
"Most analysis builds off of previous work rather than net-new exploration: 88% of queries by Data Scientists rely solely on tables they've queried in the preceding 90 days."
(ほとんどの分析は新規探索ではなく、過去の作業の上に積み上がる:Data Scientist のクエリの 88% は、自分が過去 90 日以内に触ったテーブルだけに依存している。)
Meta DWH は 数百万のテーブル を持つ規模ですが、個別アナリストの実作業範囲は 過去 90 日に触れたテーブル に集中しています。これを根拠に、Meta は personalized context を設計の中核に据えました。
設計フローはオフライン LLM のバッチ処理:
各従業員の過去クエリを 全件 オフライン LLM で処理
触れたテーブル・使い方・分析タイプの説明文を生成
生成サマリ + サンプルクエリ + カラム単位ドキュメントを継続的に更新
ストレージに格納し、Agent が必要時に取り出す
"Offline LLMs process every query an employee has run, generating descriptions of the tables they use, how they use them, and what kinds of analyses they perform."
(オフライン LLM が各従業員の実行したクエリを全件処理し、使っているテーブル / 使い方 / 行っている分析の種類を説明文として生成する。)
ポイントは、「クエリ時に LLM が schema を理解する」のではなく 事前に context を作っておいて、必要なときに取り出す という設計思想に倒していることです。
成果として、週末プロトタイプから 6 ヶ月後に Data Scientist / Data Engineer の 77% が weekly active、加えて DS/DE 利用者の約 5 倍規模 の非データロールが利用、というスケールに到達しました。
Meta 自身、この設計判断を 1 行に凝縮して書いています。
"An AI agent without personalized context is just a chatbot with database access. Context is what transforms it into a domain expert."
(personalized context のない AI Agent は、データベースにアクセスできるだけの chatbot に過ぎない。それを domain expert に変えるのが context だ。)
なお、Meta は context を Cookbook / Recipe / Ingredient という独自の語彙で構造化しています。Recipe は「シニアアナリストならこう答える」という分析手順 SOP、Ingredient は semantic model や wiki ページの構造化ナレッジ、Cookbook はそれらを束ねたドメイン入口パッケージ、という階層です。OpenAI の 6 層と命名は違いますが、schema 以外の業務知識を取り出せる形に整理する という骨格は同じです。

4. 共通点 — "context engineering" の本質
OpenAI と Meta の構造を並べると、両者とも次の共通項を持っています:
schema metadata だけでは Agent は使い物にならない
コード / 人間が書いたメモ / 業務文脈 を取り出せる形に整理する
オフラインで事前構築 + 必要なときに取り出す をパイプラインの骨格に据える
個人の文脈 を持たないと domain expert にならない
「context engineering」 は流行語的に響きますが、両者の事例を見ると実装は地味です。「schema 以外の組織知(コード / 人間が書いたメモ / Slack / 過去クエリ / 訂正履歴)を取り出せる形に整理して、必要なときに引ける状態を保つ」 という作業に近い。
OpenAI が "Lessons learned" として挙げている 3 つも示唆的です。
tool を絞る — 重複機能は Agent を混乱させる
手順を細かく書き込んだ prompt を避ける — 細かい指示より抽象度の高い方針を渡す方が GPT-5 の推論を引き出せる
curated / smaller > large / noisy — 評価実験で context は量より質が勝る
context は足せばよいわけではなく、整理されたものを少なく という運用知が滲んでいます。
5. 中堅企業の現実 — 3 つの懐疑視点
ここまで OpenAI / Meta の華々しい事例を並べましたが、これらは規模的にも組織的にも極端で、そのまま中堅企業に適用できるわけではありません。先回りして論点を整理します。
5.1 規模の前提が違う
OpenAI 600 PB / 70k datasets / 3,500+ users、Meta 数百万テーブル / 70,000+ 従業員、というスケールに対し、中堅企業は数 TB / 数百〜数千テーブル / 数十〜数百ユーザーが現実的なレンジです。6 層全部が同じ重みで必要とは限りません。層 4 の Slack / Notion 統合などは、社内ドキュメンテーション文化が無い組織では空白になります。
5.2 週末プロトタイプの裏側
Meta の "週末プロトタイプ → 6 ヶ月で全社展開" は刺激的ですが、その裏には継続的なエンジニアリングコストがあります。Vercel が公開している事例 We removed 80% of our agent's tools では、内製 text-to-SQL agent "d0" を 18 個の tool で構築 → 80% accuracy 止まり → 結局 tool を 2 個に削って書き直したら 100% accuracy、という顛末が公開されています。
5.3 内製は成功率が低く、撤退も多い
MIT Project NANDA の調査(150 リーダー interview + 350 名 survey + 300 deployment 分析)によれば、内製の成功率は外部 vendor 経由 (67%) の約 1/3。"95% の generative AI pilot が失敗" という見出しの裏側にこの数字があります。S&P Global の 2025 サーベイ(北米・欧州 1,006 名)では、「過半数の AI initiative を本番到達前に廃棄」した企業が 17% (2024) → 42% (2025) に倍増。Gartner も 40%+ の agentic AI プロジェクトが 2027 末までに cancel と予測しており、内製のまま走り切れる組織は少数派です。OpenAI / Meta の "成功事例" だけが共有されている裏で、撤退・縮小した内製 Agent は表に出てきません。
ここまでの 3 点をまとめると、OpenAI / Meta の構造を そのままコピーする のは現実的ではなく、サイズに合わせた段階的構築 か、既成プロダクトを使う か、という選択になります。これが Skeptics の核です。
6. Codatum としての見方
私たちは、"context engineering" を 組織知の整理 として捉えると、内製 / 既製の二者択一は誤った構図だと考えています。実態は次の 3 つの選択肢があります:
完全内製 — OpenAI / Meta 路線。組織規模とエンジニアリングリソースが揃う場合のみ
完全既製 — vendor の AI BI / 内蔵 Agent 機能を導入。context 整理は vendor 任せ
ハイブリッド — 既成プロダクトの context 設計力を借りつつ、社内固有の知識(業務 metric 定義 / ドメイン知識 / 訂正履歴)だけ自前で乗せる
Codatum は 3 番目の選択肢の側で動いています。
具体的には、層 1(dbt 連携の schema・lineage・過去 SQL)を直接持ち、層 2 / 層 4(テーブル説明・分析レポートが蓄積される institutional knowledge の置き場)として notebook 環境を提供しています。
一方、層 3(コードから LLM が自動抽出する経路)、層 5(Agent の訂正記憶)、層 6(Agent が実行時に直接叩く経路)は Codatum 単体には含まれず、Agent 実装と組み合わせる前提です。
OpenAI 自身が "Lessons learned" で「tool は絞った方がいい」「context は curated/smaller の方が large/noisy より勝つ」と書いているように、6 層全部を内製で組み上げる のは費用対効果が悪くなります。中堅企業の現実解は、"自社固有の業務知識だけ context 化する" というスコープ縮約です。
7. これから — 内製 / 既製どちらでも要る準備
具体的には、内製で行くにせよ既製を入れるにせよ、データチーム側で準備しておくと結果が変わる 4 つを挙げます。いずれも OpenAI / Meta が共通して必要としていた要素です。
7.1 スキーマ説明文の整理(OpenAI 層 2 相当)
業務的に重要なテーブル・カラムに、「これは何で、どう使うべきか」のテキスト を 1-2 文で書いておく。これが無いと、内製でも既成でも Agent は schema metadata 止まりになります。dbt の description: フィールドや、社内 wiki に書く形で十分です。
7.2 metric 定義の文書化(OpenAI 層 2 / 4 相当・Meta Recipe 相当)
「Active User の定義」「Churn の計算ロジック」「会計売上 vs 出荷売上」のような canonical definition を、Slack や口承ではなく文書として持つ。dbt Semantic Layer / OSI / Power BI semantic model のような形でも、内製 wiki でも十分です。これが無いと Agent は「同じ metric を別解釈で計算する」事故を起こします。
7.3 過去の分析の蓄積 — 「実際にこう使った」例が context に残るか(OpenAI 層 4 / Meta personalized context 相当)
7.2 の metric 定義が骨組みなら、ここはそこに肉付けする層です。「あるテーブルを誰がどう使って、どう加工して、どう解釈したか」の 過去の分析プロセス が残っていることが、Agent から見て生きた context になります。
Meta の「Data Scientist のクエリの 88% は過去 90 日に自分が触ったテーブル」はまさにこの構造で、過去の自分の作業が Agent の context として戻ってくる。OpenAI 層 4(institutional knowledge)のうち、Slack / Notion ではなく 「実際の SQL + 出力 + 解釈」 の部分にあたります。
具体的には、SQL + 出力 + analyst の commentary が一箇所に保存・検索できる場所 が必要です。notebook 環境(SQL を書いて、結果を見ながら、解釈を書いて、共有する)に近い形が、過去分析を生きた context として取り出しやすい。dbt の description: だけでは伝わらない「実例としての context」が、Agent から取り出せる形で残っているか、というレイヤーです。
7.4 利用テーブルのトレーシング(Meta 88% 観察相当)
社内のクエリ履歴から「過去 90 日に誰がどのテーブルを触ったか」を見えるようにしておく。Meta の "88%" 観察は、この履歴が見えないとできない設計判断です。クエリログの保存と簡単な集計だけで、Agent の context retrieval 設計が一段詳細になります。
これら 4 つは、Codatum を導入するかどうかと関係なく投資価値があります。逆に言えば、この 4 つが揃っていない状態で Agent を入れても期待値が出ない のは、OpenAI / Meta が共通して示しているとおりです。
おわりに
OpenAI と Meta の事例を並べると、内製データ Agent の中核は "schema 以外の組織知を取り出せる形で整理しておく" という地味な作業に尽きる、と見えてきます。OpenAI は 6 層、Meta は Cookbook / Recipe / Ingredient と命名は違いますが、骨格は同じです。
Codatum は、context engineering を組織知の整理として捉え、社内固有の知識だけ自前で乗せて、それ以外は既成プロダクトに任せる ハイブリッドの側で動いています。完全内製でも完全既製でも、最初の一歩(スキーマ説明・metric 定義・テーブル利用ログ)は同じです。そこから先、自分達のリソースとスケールに合わせて、内製の幅を決めていく。