Contents
ソフトウェアを顧客ごとにどこまで深くカスタマイズするか。これを長く縛ってきたのはコストですが、効いていたのは作る時の費用だけではありません。深く作り込んだシステムは、その後も運用し、修正し続けなければなりません。深さの本当のコストは、作る費用ではなく、抱え続ける負担にありました。だからこそ深いカスタマイズは、その負担を負える限られた経済性の上でしか成立しませんでした。
この前提を、コード生成エージェントが部分的に崩しつつあります。作り込みの担い手が人間からエージェントへ移れば、少なくとも作る費用は下がります。ただし、運用や保守の負担まで消えるわけではありません。だから「どこまで作り込むか」は、予算が自動で決める問題ではなく、適合と負担を天秤にかける設計上の選択になります。
本稿は、この選択を「ソフトウェアのどの層まで個社ごとに生成するか」という軸として整理し、各層を選んだときに何が得られ、何が失われるかを、既存の製品と先行する議論に照らして検討します。そのうえで最後に、その地図がいま指している、まだあまり埋まっていない一マスについても触れます。
下がっていくカスタマイズコスト
ソフトウェアを顧客ごとに深くカスタマイズする手段は、長らく人手でした。Palantir の Forward Deployed Engineer(FDE) がその典型です。エンジニアが顧客の現場に入り、その企業専用にシステムを構築します。手間と単価が大きいため、この方式が成立するのは大型のエンタープライズ契約に限られていました。
コストを避けるため、多くのソフトウェアは浅い固定点を選びました。SaaS がその代表です。アプリケーション本体は全社共通に固定し、各テナントが触れるのは設定や画面構成にとどめます。深いカスタマイズを諦める代わりに、低コストで多数の顧客に同一の製品を届ける。逆に、カスタマイズを深くするほどアップグレードや保守、外部との統合が難しくなることは、ERP のカスタマイズ負債として古くから知られてきました。SAP 自身も、過度なカスタムコードがアップグレードを遅らせ総保有コストを高めると指摘し、中核を不用意に書き換えない設計(clean core)を推奨しています。
深いカスタマイズが大企業に限られてきたのは、作る費用が高いからだけではありません。作り込んだ分だけ、その後の運用・保守・改修を自前で抱え続ける必要があり、その負担を負えるのが一部の大企業に限られたためです。深さを縛っていたのは、作る費用ではなく、抱え続ける負担でした。
ここにエージェントが新しい変数を持ち込みます。担い手が人間の FDE からエージェントへ移れば、作る費用は下がります。ただし、抱え続ける負担までは下げきれません。だから深さは「予算が許すか」ではなく**「適合に見合う負担を負うか」**という、設計上の判断に変わります。
何を生成「できるか」ではなく、どこまで生成「すべきか」
問いを取り違えないことが重要です。エージェントをめぐる議論は「どこまで生成できるか」に向かいがちです。しかし生成のコストが下がり、どの層でも生成可能になるほど、本質的な問いは**「どこまで生成すべきか」**——深く生成したとき利用者に何が得られ、何が失われるか——に移ります。能力の問いではなく、価値の問いです。
範囲も限定しておきます。生成には「何の単位で生成するか」という粒度の軸があります。会社(個社)単位か、利用者単位か、操作のたびのその場生成か。本稿は個社単位に絞ります。利用者単位・その場単位の生成はより複雑な別の主題であり、ここでは扱いません。ただし後述する最上層では、この軸が一度だけ関わってきます。
地図:4つの層
一般的なソフトウェアは、おおまかに4つの層から成ります。
UI — 見え方と操作の導線
app — 振る舞い、機能、手順
db — データモデル。何が存在し、どう関係するか
infra/auth — それらが動作する土台と、誰が何に触れてよいかを定める権限
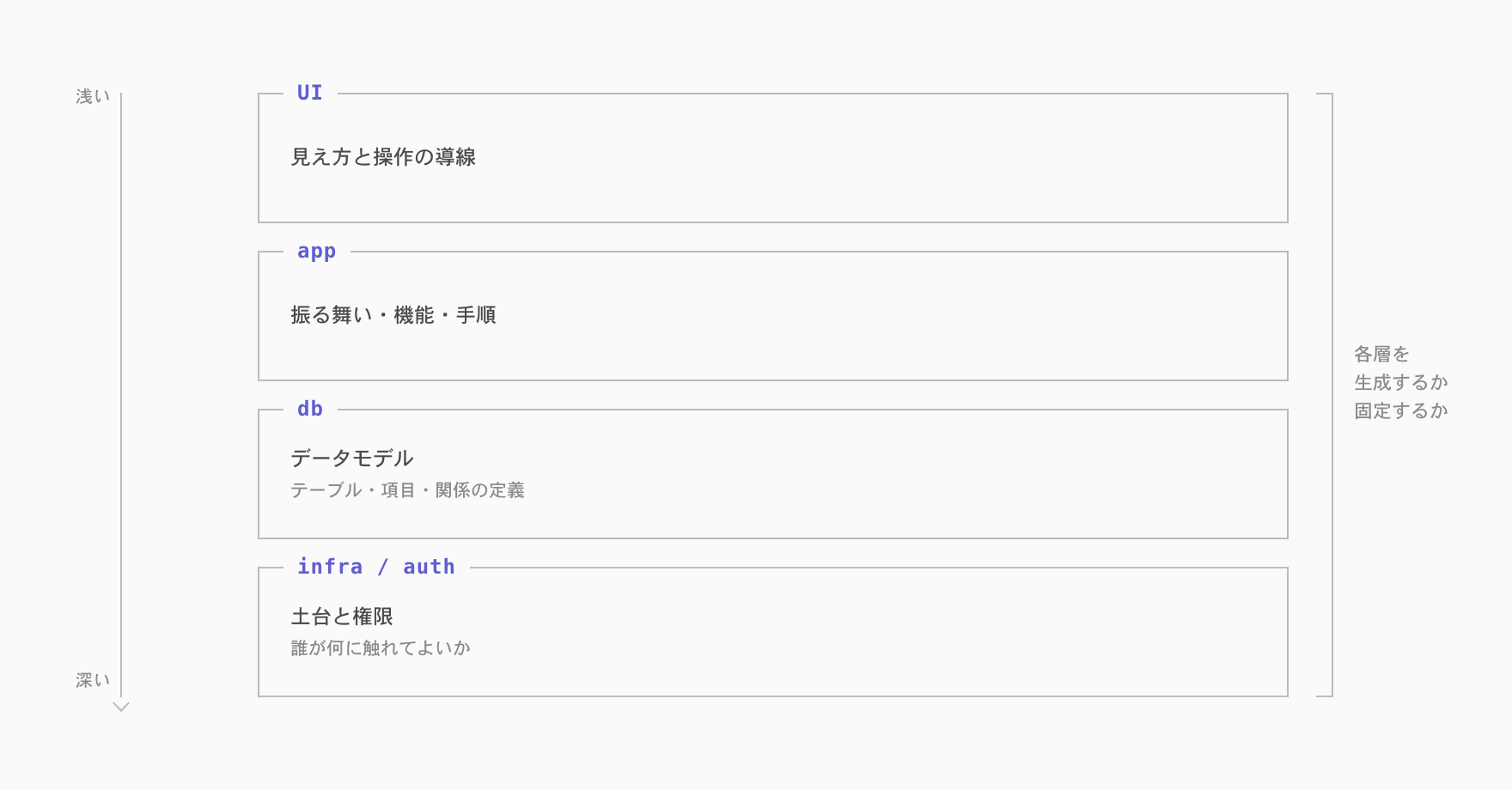
「どこまで生成するか」とは、この積層のどこまでを個社ごとに作り替えるかという問いです。UI だけを各社に合わせるのか、振る舞いまで降りるのか、データモデルそのものを作り替えるのか。
最下層の infra/auth は、扱いがやや特殊です。ここは生成するか固定するかという選択そのものが論点になるため、最後に改めて扱います。まずは上の3層を、生成がどこまで降りるかの目盛りとして見ていきます。
どの層を固定化して、どの層をGenerateするべきか
層を降りるにつれ、一つの規則性が現れます。深く生成するほどシステムは個社に適合しますが、その分だけ、本来プロダクトが肩代わりしていた負担を自分で抱え込むことになります。
これが本稿の軸です。深さは、適合(自社への適合度)と負担(自分で抱える構築・運用・コスト)の間のトレードオフを動かす変数になります。共有されたプロダクトは、構築も運用もセキュリティも保守も、全顧客で按分して肩代わりしています。個社ごとに生成すると、その按分が効かなくなり、生成した分だけ負担が自社に返ってきます。SAP も、過度なカスタムコードがアップグレードを遅らせ総保有コストを高めると認め、中核を不用意に書き換えない設計(clean core)を勧めています。注目すべきは、抱える負担が、層を深く降りるほど重く、多面的になる点です。
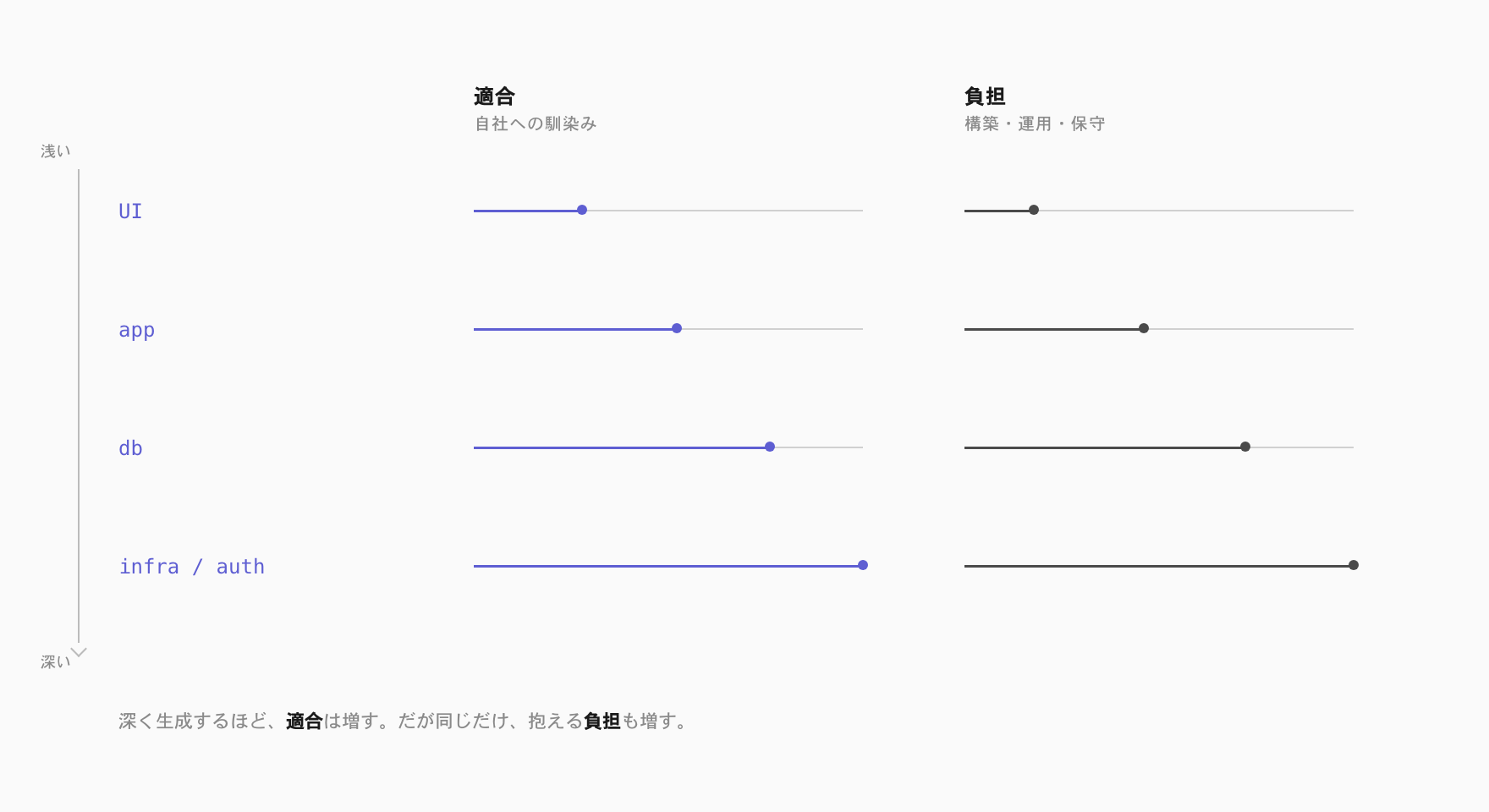
UI だけを生成する場合、抱える負担は比較的軽く済みます。画面は状態を持たず作り直しが効き、下にある共有された核が構築・運用・セキュリティを引き続き肩代わりするからです。
そこから下、データモデルとそれを操作するロジックの核まで生成すると、負担は段違いに重くなります。生成された自社固有のロジックの正しさ、データモデルの整合、migration、bugfix、バージョンアップを、丸ごと自分で抱えることになる。ロジックは、それが操作するデータモデルが自社専用になって初めて意味を持つので、両者は切り離せず、ひとかたまりで降りてきます。
抱える負担は、画面の作り直しから、核(データとロジック)の保守へと、深く降りるほど重くなります。適合と負担は、一方を取れば他方が膨らむ関係にあります。
UI/APIの層 - Frontの生成
ここまで「深く生成する」方向で述べてきましたが、現在もっとも活発なのは逆方向——最上層の UI です。しかも、その中身が変化しています。
UI を個社ごとに作り込むこと自体は、もともと一般的ではありませんでした。多くの製品は画面を全社共通に固定し、深く作り込む場合も人手で個別に開発するだけで、画面を実行時に生成してきたわけではありません。
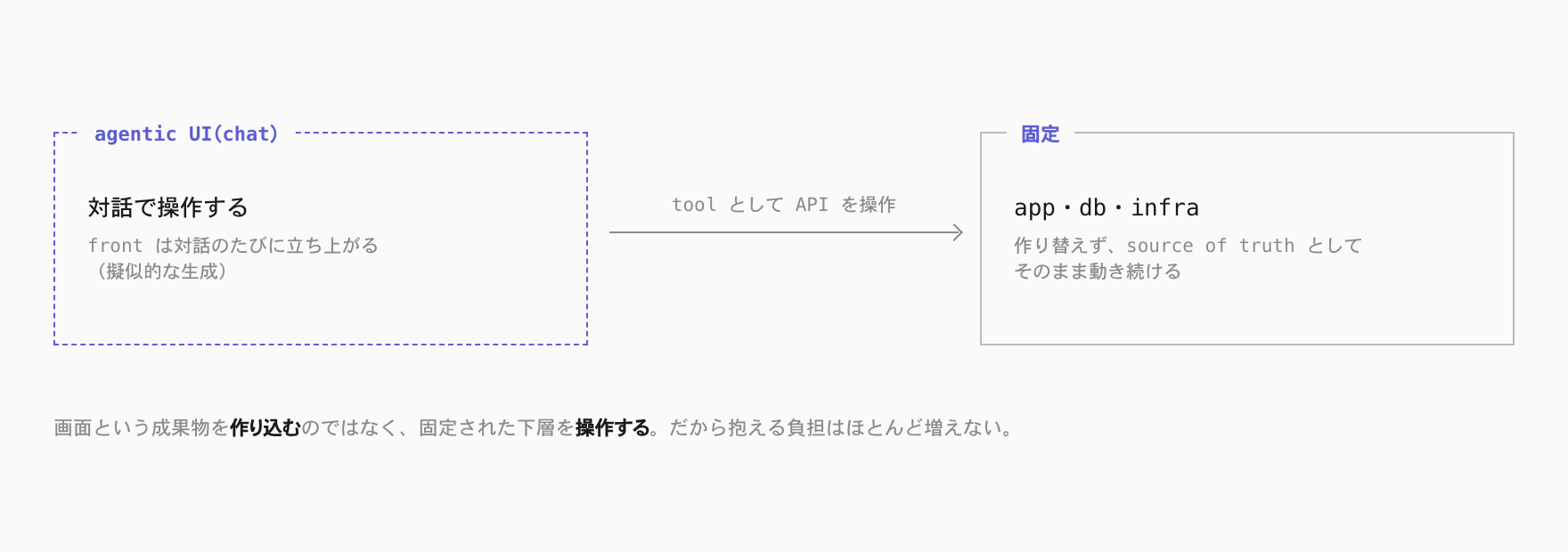
その UI が、いま生成の対象になりつつあります。ただし、企業ごとに専用画面を作り込むのではありません。app の機能を tool として API で公開し、その API を agentic な UI——多くは chat UI——に操作させる。固定された画面の代わりに、対話のたびにインターフェースが立ち上がります。いわば、擬似的な front の生成です。
実例は多くあります。Salesforce の Agentforce、Notion の Notion AI、ServiceNow の Now Assist など、データモデルを固定してきた各社が、その上に対話エージェントを乗せています。土台の object model やデータ構造はそのままに、操作の窓口だけをエージェントに置き換える構成と読めます。これを支えるのが、Anthropic が2024年11月に公開した MCP (Model Context Protocol) のような、アプリの機能を tool としてエージェントへ開く規格であり、API を tool として束ねる作法が標準化しつつあります。
この構成が広がる理由は二つあります。
第一に、下層を触らずに済みます。データモデルも振る舞いも固定したまま、最上層に対話エージェントを一枚加えるだけで十分です。各社が長年構築してきた object model も、その上の振る舞いも、source of truth としてそのまま動作し続け、エージェントはその固定された土台を操作する窓口になります。
第二に、抱える負担がほとんど増えません。概念も振る舞いも全社共通のまま据え置かれ、構築・運用・セキュリティは下の共有 app が肩代わりし続けます。変わるのは「どう操作するか」という対話のその場限りの部分だけです。前節で述べた「深く生成するほど負担を抱える」という代償を、この構成はほとんど払わずに適合を得ます。トレードオフの手前に位置する選択であり、最初の一歩として採られやすい構成です。
ここで、保留していた粒度の軸が一度だけ関わります。概念や振る舞いをその場ごとに作り替えるのは複雑で扱いにくいとして除外しました。しかし操作型は、その場ごと(対話のたびに異なる動作)で機能し、かつ破綻しません。生成が浅い層にとどまるためです。下層が固定されている限り、エージェントが毎回異なる操作をしても、可能な動作は固定された API の範囲に収まります。深い層では危険なその場生成が、最上層でのみ安全に成立します。深さと粒度は独立ではなく、ここで噛み合います。
ただし、得られる適合には上限があります。エージェントが操作できるのは、用意された tool の範囲に限られます。「どう頼むか」は自由になりますが、「システムに何ができるか」「どの概念で世界を捉えるか」は固定されたままです。それ以上の適合を求めれば、app、db へと降りることになります。
注目したいのは、これらの製品が降りていない領域です。Agentforce も Now Assist も、データモデルの作り替えには踏み込んでいません。固定した object model の上に操作層を加えただけです。もっとも活発な動きは、もっとも浅い層で起きています。普及の中心と、製品の性格を決める判断は、層が異なります。
DB/Logicの層 - 幅広い業務の代替
最上層の動向から視線を下げると、製品の性格を決めている境界が見えてきます。データモデルと、それを操作するロジック——いわば DB/Logic の核——を、共有のまま固定して上で構成するか、それとも個社ごとに生成するか。製品の性格は、この核を固定するか生成するかで決まります。
立ち方は二つです。一つは、核を全社共通に固定し、その上を構成(config)と限定的な拡張で各社に合わせる立ち方。もう一つは、核そのものを個社ごとに生成する立ち方です。
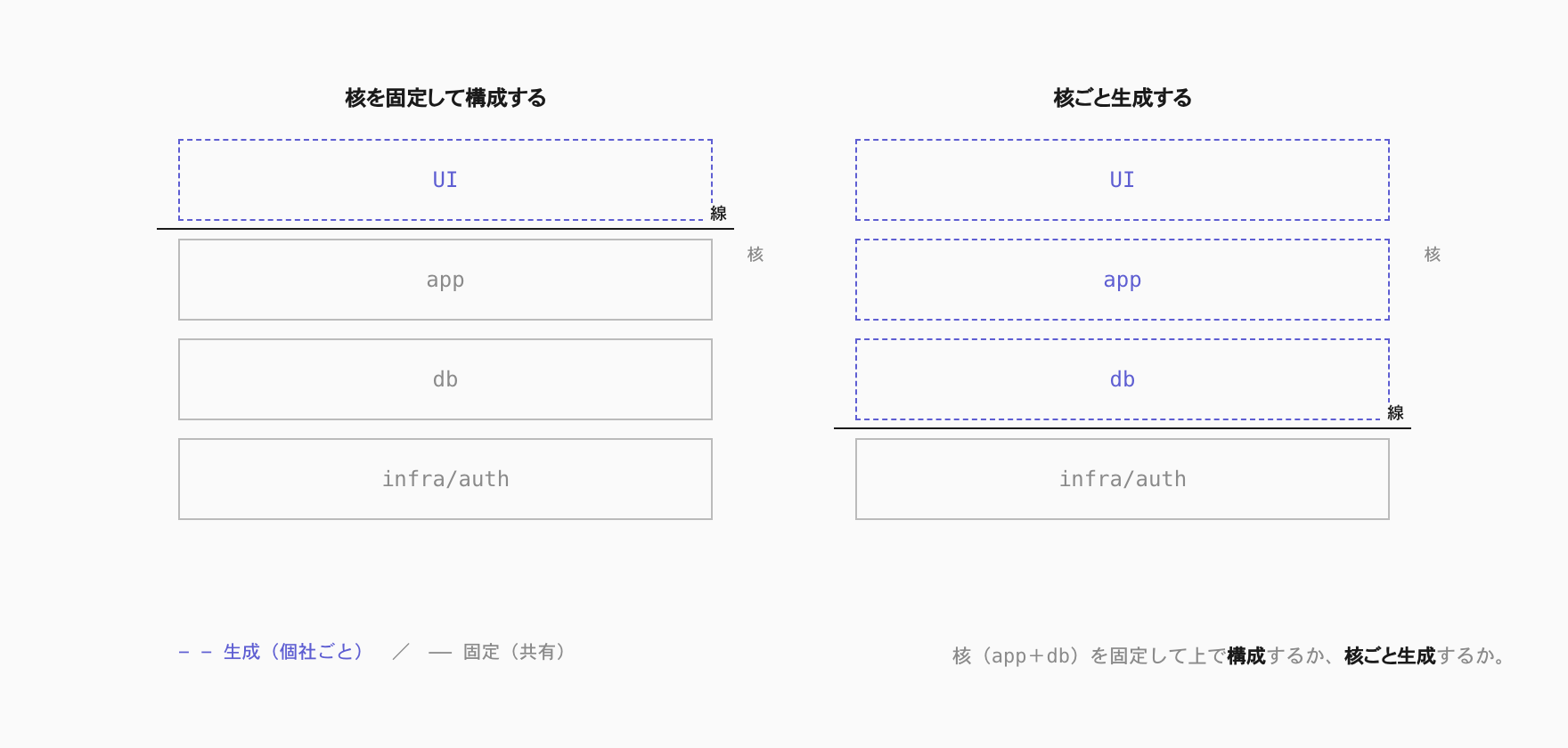
広く普及した製品の多くは、前者です。Salesforce は Account・Contact・Opportunity という標準オブジェクトを共有の核として固定し、各社は custom field の追加や workflow・view の構成でそれに合わせます。Notion も database と property type という primitive を固定し、その枠内で構成する。これは「振る舞いを生成している」のとは違って、固定された核の上での構成・拡張です。サーバサイドのロジックは、それが操作するデータモデルが自社専用になって初めて効くので、データモデルを共有したまま振る舞いだけを生成しても旨みは小さい。だから核は、データとロジックがひとかたまりで動きます。
核を固定する利点は、その保守をベンダーに残せることです。データモデルの整合も migration もバージョンアップも、全顧客分まとめてベンダーが引き受ける。各社は構成に集中できるし、概念が共通な分、連携も人材の可搬も効きます。
もう一方が、核ごと生成する型です。近年は「利用のたびに専用のデータモデルとロジックを起こす」エージェント型が現れ、汎用の「Project / Task」に自社を合わせるのではなく、自社の語彙でシステムが立ち上がります。適合の深さは、構成では届かない水準に達し、幅広い業務をそのまま代替できます。
代償は、生成した核の保守を丸ごと自社が抱えることです。スキーマの整合、migration、bugfix、バージョンアップ——共有プロダクトが按分していた負担が、すべて自社に返ってきます。
ここに、本稿のトレードオフがもっとも鋭く現れます。核を固定して構成にとどめるか、核ごと生成して適合を取りにいくか。それは「どこまで自社に馴染ませるか」と「どこまで保守を自分で背負うか」を同時に決めています。
Infra/Authの層 - FDEか固定化か
最下層の infra/auth まで降りると、何が起きるか。ここを自前で構築するのは、特殊なことではありません。専用のインフラ・権限・セキュリティまで顧客ごとに作り込むのは、むしろ古典的なやり方です。Palantir の FDE が顧客先で組み上げてきたのは、まさにこの全部入りのシステムでした。Foundry は、ontology から dynamic security(動的な権限制御)まで顧客固有に構築します。汎用の概念に合わせるのではなく、その企業の概念・関係・権限の体系ごと作り上げる。適合は、ここで最大になります。
代わりに、抱える負担も最大になります。構築だけでなく、運用・セキュリティ・可用性・bugfix・アップグレードまで、すべて自社(あるいは作り込んだベンダー)が持つ。a16z のパートナー Marc Andrusko は、Palantir の手法を表層だけ模倣すると「維持もアップグレードも不可能な、無数の個別構築の集まり」に陥ると指摘しています。適合を極めた先には、保守不能の危険が口を開けています。
概念やインフラまで降りる型が、歴史的に Palantir のような高単価・高タッチの FDE 経済性でしか成立しなかったのも、この負担の重さゆえです。深さは、一部の大型顧客だけの選択肢でした。いま、その前提をエージェントが変えつつあります。構築も migration も、人手の FDE を張り付けずに回せるなら、深さの経済性は変わります。ただし、構築のコストが下がっても、運用・セキュリティ・保守の負担までゼロになるわけではありません。生成は一度きりでも、抱えた負担は使い続けるかぎり残ります。
もう一方の選択が固定化です。infra/auth を自前で作らず、managed なプラットフォームに委ねる。適合と制御は手放しますが、構築・運用・セキュリティの負担をまとめて按分に戻せます。多くのチームがこの層を固定するのは、神聖だからではなく、ここで得られる適合の旨みが小さく、抱える負担が最大だからです。差別化が生まれるのは、インフラではなく、その上の業務側です。
固定にはもう一つ効用があります。誰が何に触れてよいかという境界を動かさずに据えれば、上層でどれだけ生成が走っても、影響はその枠の中に収まります。固定した土台が、上の自由な生成を安全に支える。逆にその設計を誤れば、上の生成すべてに統制不能の穴が空きます。
どの戦略を取るか
「どの深さまで生成させるのが正解か」に、普遍的な答えはありません。深さは正解を持つ目盛りではなく、適合と負担のトレードオフ上で立ち位置を選ぶための目盛りにすぎません。

UI で止めれば、負担をほとんど増やさずに操作の適合が手に入りますが、できることの幅は広がりません。データモデルとロジックの核まで降りれば、自社の語彙でシステムが立ち上がる代わりに、その保守を丸ごと背負います。infra/auth まで降りれば、最大の適合と引き換えに、運用もセキュリティも抱えることになる。各社の製品コンセプトの違いも、突き詰めればこの立ち位置の差です。Salesforce や Notion が核を固定して構成にとどめ、Palantir が下まで降りるのは、優劣ではなく、適合と負担のどちらをどれだけ取るかの違いにすぎません。
そして、この地図にはまだあまり埋まっていないマスがあります。いま実際に多いのは両端で、UI に agentic な皮をかぶせて下は全部固定するか、FDE で下まで丸ごと作り込むか、のどちらかです。その中間——infra/auth は managed のまま固定して、DB/Logic の核だけを個社ごとに生成する型——は、まだあまり見かけません。けれど負担の地図で見ると、ここが一番おいしいはずなんです。infra/auth は負担が重くて差別化も生まれにくいから固定したいし、DB/Logic の核は適合がいちばん効く。これまで核を個社生成するには FDE の経済性が要って、その勢いで auth まで作り込むのが普通でしたが、生成が安くなって managed な土台も当たり前になったいま、この二つは切り離せます。だから「auth は固定、DB/Logic は生成」という組み合わせが、これから出てくるんじゃないかと思っています。
もちろん、これはまだ賭けです。最大の未解決点は、エージェントが構築コストを下げても、運用・セキュリティ・保守の負担まで軽くできるのか、というところで、大規模な専用コードの作り替えを大幅に短縮した事例(Cognition の Nubank 事例など)は出てきているものの、生成した核を使い続けるかぎり保守の負担は残ります。下がるのが作る費用だけなのか、抱える負担そのものなのか。そこで、この組み合わせがどこまで広がるかが決まります。
データ分析の場合
本シリーズが扱ってきたデータ分析は、ここまでの議論のなかでも特殊な一例です。そもそも、固定された一つのデータモデルがありません。任意のデータモデルと任意の要件に応えることが前提で、だからチャートやダッシュボードといった UI は、もともと多様で、自由度高く作られています。
Codatum でも、チャートやダッシュボードのカスタマイズ自由度は高く、要件に合わせて相当な作り込みができます。そこにエージェントが加わると、個別の SQL を実行し、その結果をチャートに描く。これは見方を変えれば、DB(クエリ)・ロジック・front のどの層も、その場で生成しているに近いと言えます。エージェントがデータ分析と相性が良いと言われるのは、この**「層をまたいで生成する」性質**が、もともとこの領域に馴染むからかもしれません。
もっとも、BI にもより headless なアプローチがあり、どこまで作り込み、どこを既製に委ねるかは一様ではありません。結局は、カスタマイズ性と運用負荷のバランスを見てツールを選ぶことになります。データ分析でも、問いは同じです——適合と負担の、どこに立つか。
本稿が示したのは、その立ち位置を測るための枠組みです。適合の魅力と、抱える負担を取り違えないための地図として使われることを意図しています。
参考文献
What is a Forward Deployed Engineer? | Gergely Orosz, The Pragmatic Engineer, 2025-08-12
The Palantirization of Everything | Marc Andrusko, a16z, 2026-01-16
How to Extend SAP S/4HANA Cloud the Right Way (Clean Core) | SAP News Center, 2025-08-12
Understand the Salesforce Architecture | Salesforce Trailhead
Exploring Notion's Data Model: A Block-Based Architecture | Jake Teton-Landis, Notion, 2021-05-18
Introducing the Model Context Protocol | Anthropic, 2024-11-25
Introducing AI SDK 3.0 with Generative UI support | Vercel, 2024-03-01