Contents
「AIに作業を任せるほど楽になるはずが、なぜ決める仕事ばかり増えるのか」。本記事は、その素朴な疲れから出発して、人間の意思決定がこの先どうなるのかを整理する解説記事です。判断は人間に残るという見方、評価や実務の判断はもうAIに渡せるという動き、そしてAIがより高次の仕事へ登っていく試みとその到達点を順に並べ、最後に「意思決定を上と下に分ける」という一つの見取り図を置きます。筆者の新説ではなく、いま出ている議論を整理したものです。
問題 ― 意思決定疲れ
AIを使い始めて、こんな感覚はないでしょうか。作業をいくつもAIに振れるようになった。けれど、出てきたものを全部見て「これでいい」「これは違う」と決めているのは、結局いつも自分です。手を動かす時間は減ったのに、決める回数のほうはむしろ増えていて、楽になるはずがそうなっていない、という感覚です。
その感覚を、心理学はdecision fatigue(決定疲れ)と呼びます。決め続けると判断の質がじわじわ落ちていく、という現象です。そこへAIが、確認と承認を待つ候補をさらに積み上げてくる。作業は肩代わりされたのに、意思決定のほうは手元に溜まっていく一方です。
だったら、その溜まっていく意思決定も、AIに渡せないのか。そう考えたくなります。ただ、この問いに対する答えは一つではありません。判断は人間に残るという主張と、もう渡せるという現場の動きが、正反対を向いたまま同時に存在しています。
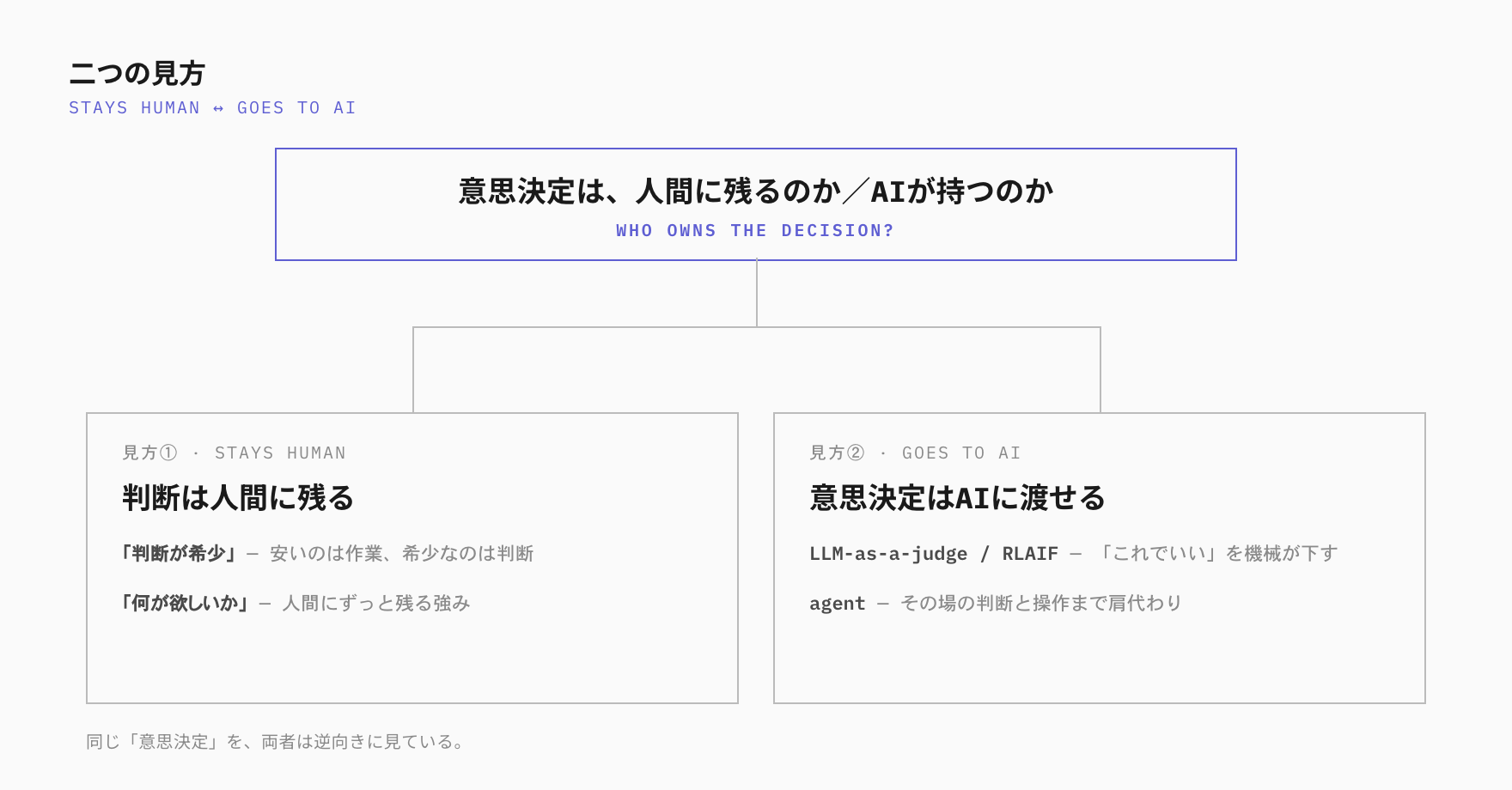
見方① ― 判断は人間に残る
片側は、「渡せない、判断は人間に残る」という立場です。AIに任せる時代の新しい役割として、Orchestrator(指揮者)という言葉が提案されています(Nova Spivack)。1人の人間が何体ものAIの上に立ち、方向を決め、情報を配り、結果をまとめ、最後の判断を下す。手を動かす作業はAIに降り、人間は頂点で「全体として何を意味するか」を引き受ける、という分担です。
根拠は、希少性の移り変わりにあります。
"Compute is becoming abundant. Judgment is becoming scarce."
(計算能力はありふれたものになり、判断は希少になっていく)
ありふれたものは値下がりし、希少なものは値上がりする。AIが作業を安く大量にこなすほど、価値は判断のほうへ寄る、という理屈です。
では、判断ごとAIに渡せばいいのか。そこは明確に否定されます。人間を頂点から外すと、出力は量ばかりで意味を失う、という指摘です。
"You can absolutely run agent swarms without a human at the top. ... plausible-sounding output that drifts, lacks taste, fails to integrate, and produces volume without judgment."
(人間を頂点に置かずAIの群れだけで走らせることはできる。だが手に入るのは、もっともらしく聞こえるのに、的を外し、センスを欠き、噛み合わず、判断のないまま量だけ積み上がった出力だ)
"The human judgment node is not a bottleneck to be eliminated. It is the organ that makes the output mean something."
(人間の判断は、取り除くべきボトルネックではない。出力に意味を持たせる器官だ)
同じ側に立つ見方は、経済学からも出ています。人間に最後まで残る比較優位は「自分が何を欲しいかを知っていること」であり、仕事の中身は「作る」から「AIの出力を検証する」へ移る、という予測です(Noah Smith)。
"the one thing humans will always be comparatively good at is knowing what we want."
(人間がずっと得意でいられる唯一のことは、自分が何を欲しいのかを知っていることだ)
この見方は、読む側には心強いものです。決定疲れは替えのきかない希少な仕事をしている証拠であり、判断こそ人間に最後まで残る、と言ってくれるからです。
見方② ― 意思決定はAIに渡せる
ところが現場は、その逆も同時に作り始めています。全部を人間が決めていては追いつかない、という、冒頭のdecision fatigueと同じ理由からです。
ひとつは、AIの出力の良し悪しを、別のAIに判定させる動き。LLM-as-a-judgeと呼ばれ、評価の定番になりつつあります。これを体系的に調べた2023年の研究では、強い言語モデルを「審査員」に使えるかを検証しました。
"we explore using strong LLMs as judges to evaluate these models on more open-ended questions."
(我々は、より自由回答的な問いでモデルを評価するために、強力なLLMを審査員として使うことを探る)
そしてGPT-4の判定は、人間の好みと80%を超えて一致した、と報告しています。といっても、これは人間同士が一致する割合とほぼ同じで、完璧な正解に並んだわけではありません。位置や長さ、自分に似た出力を高く見るといった偏りも残っていて、人間が書いた手本を外すと一致率は落ちる、という研究もあります。それでも、「これでいい」という判断の少なくとも一部が、すでに機械の手に渡り始めていることは確かです。
もうひとつは、学習の場面で、人間の評価そのものをAIの評価に置き換える動き。AnthropicのConstitutional AI(2022)は、出力の良い・悪いを人間がラベル付けする代わりに、原則のリストを渡したAI自身に評価させ、その評価で学習を回します(RLAIF)。狙いは、decision fatigueの集団版を解くことです。
"As AI systems become more capable, we would like to enlist their help to supervise other AIs."
(AIがより有能になるにつれ、他のAIを監督する仕事にもAIの力を借りたい)
人手では追いつかない、だから評価という意思決定をAIに肩代わりさせる。Anthropicはこれを、いずれ人間より有能なモデルを監督するための足がかり(scalable oversight)と位置づけています。
評価だけではありません。顧客対応のように、その場の判断と操作をまるごとagentに任せる試みも進んでいます。Sierraのτ-benchは、ルールに従って客とやり取りしながらツールを動かすagentを測るベンチマークで、単発の成功率は、新しいモデルになると小売タスクで8割を超えるところまで伸びました。ただし、同じ課題を何度も続けて通せるか(pass^k)で見ると、話は変わります。当初の評価では、最高水準のモデルでも小売タスクの半分も通せず、8回続けて成功できた割合(pass^8)は25%を切りました。8回に1回はどこかで失敗する、という水準です。一回はこなせても毎回は当てにならず、下の判断を渡せても、まだ任せきりにはできない、という段階です。
こうして見ると、「判断は人間に残る」は、もう自明ではありません。
見方②の先 ― さらに高い層へ
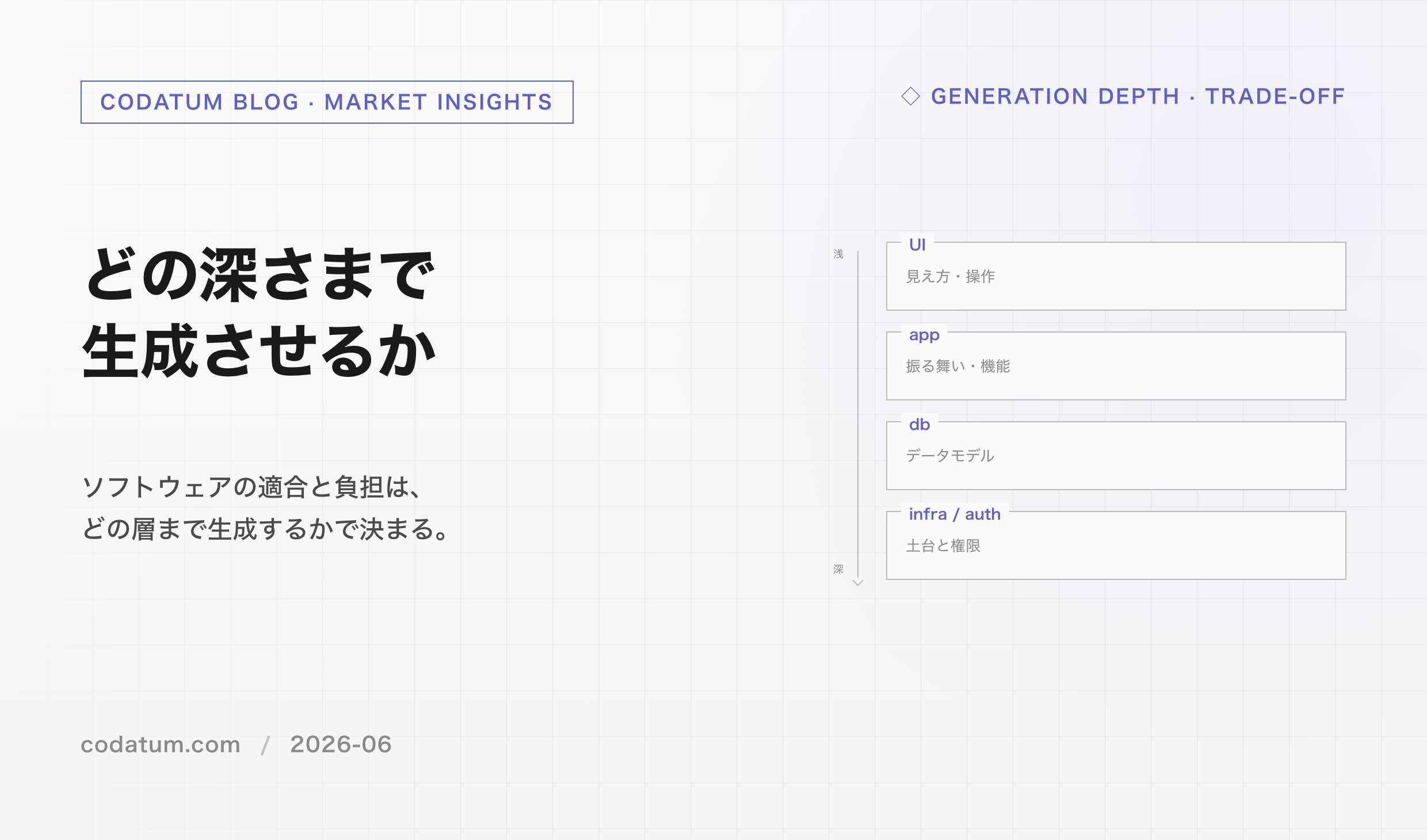
見方②の動き――意思決定をAIに渡す――は、評価のところで止まりません。同じ流れが、もう一段上の層まで伸びています。これまで人間が握っていた「束ねる」「設計する」、さらには「自分を直す」といったメタな仕事まで、AIにやらせる試みが出てきました。下から順に、三段に見えます。
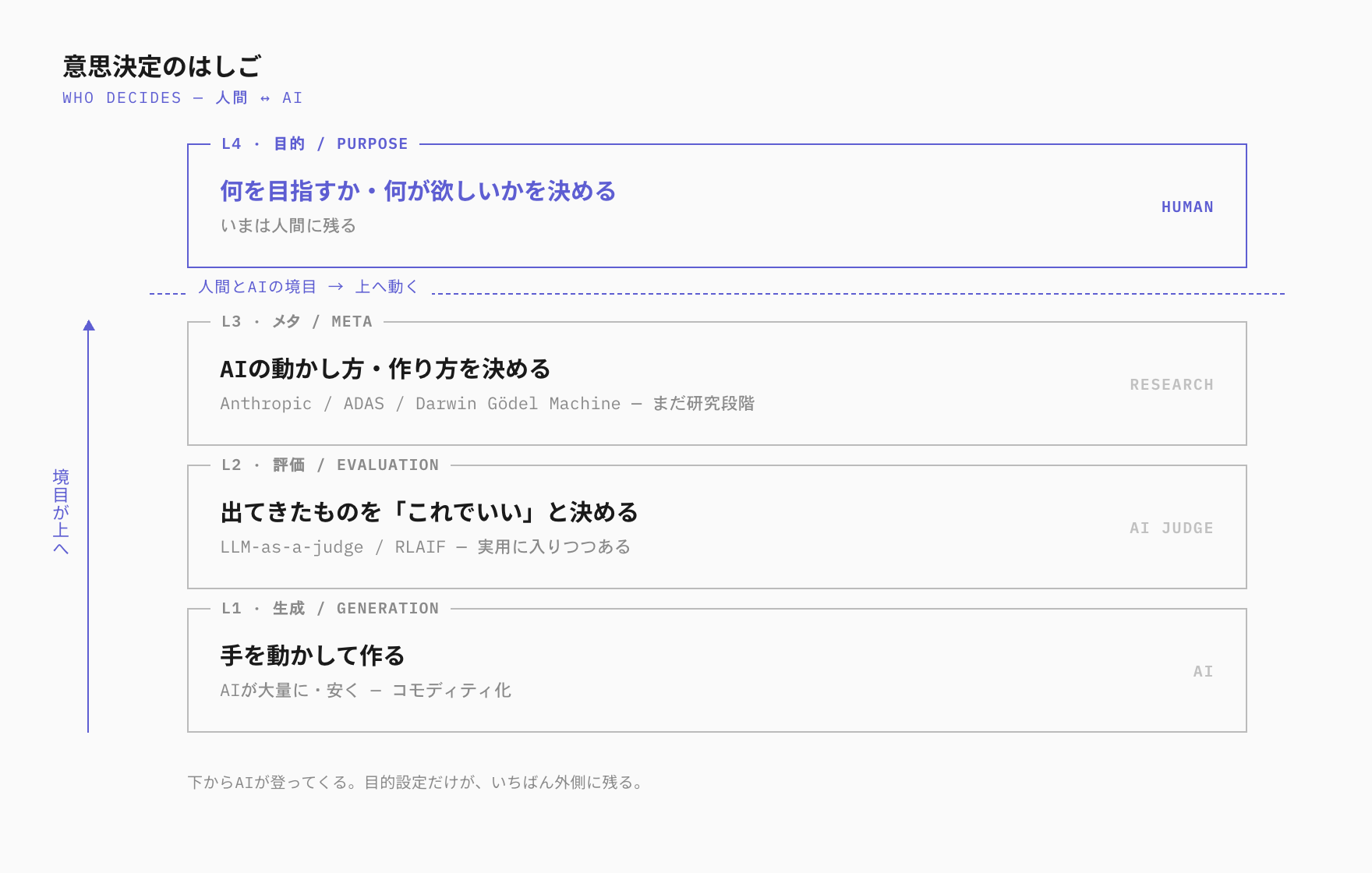
一段目は、束ねる役をAIが担うこと。Anthropicは2025年、複数のAIを使う調査システムを公開しました。リードのAIが計画を立て、専門のAIに作業を振り、結果をまとめます。
"Our Research system uses a multi-agent architecture with an orchestrator-worker pattern, where a lead agent coordinates the process while delegating to specialized subagents that operate in parallel."
(我々の調査システムは、リードagentが全体を統括し、並列で動く専門subagentに作業を振る、orchestrator-worker型の構成をとる)
さきほど人間の仕事として挙げた「統括・分配・統合」を、ここではAIが肩代わりしています。
二段目は、AIがAIを設計すること。ADAS(Automated Design of Agentic Systems, 2024)では、「meta agent」がコードを書いて新しいagentを次々に生み出します。
"the history of machine learning teaches us that hand-designed solutions are eventually replaced by learned solutions."
(機械学習の歴史は、人手で設計した解がいずれ学習された解に置き換えられる、と教えている)
三段目は、AIが自分自身を書き換えること。Sakana AIらのDarwin Gödel Machine(2025)は、自分のコードを直して性能を上げるcoding agentで、コーディングのベンチマークで成績を20%から50%へ自力で伸ばしました。
"There is growing hope that the current manual process of advancing AI could itself be automated."
(AIを進歩させる、いまは人手のプロセスそのものを、自動化できるのではという期待が高まっている)
しかも、この方向はすでに研究室の外でも成果を出しています。Google DeepMindのAlphaEvolve(2025)は、LLM自身にコードを書き換えさせて改良を重ねるシステムで、実際に本番へ投入されました。データセンターのジョブ配置を見直して、本来なら遊んでしまう計算資源をサーバー群全体で平均0.7%回収し、Geminiの学習に使う行列計算カーネルを23%速くして、学習時間そのものを1%縮めています。さらに、4×4の複素行列の掛け算を48回の乗算でこなす方法を見つけ、Strassenのアルゴリズム以来56年ぶりに記録を塗り替えました。
ただし、ここには共通の留保がつきます。Darwin Gödel Machineの一回の実行はおよそ二週間・2万2千ドルかかり、書き換えられるのは道具や手順までにとどまります。Anthropicの調査システムも普通のチャットの15倍のトークンを使うため、割に合うのは価値の高いタスクに限られます。そしてAlphaEvolveがここまでの成果を出せたのは、計算資源の量にせよ、カーネルの速度にせよ、数式の正しさにせよ、「良くなったか」を機械が自動で測れる問題だったからです。良し悪しを自動で採点できない場所には、まだ手が届きません。それでも、進んでいる向きそのものははっきりしています。

最後に ― 「意思決定」を分割する
見方①と見方②は、正面からぶつかっているように見えて、じつはすれ違っています。どちらも「意思決定」と一語で呼んでいますが、指しているものが違うように感じます。
意思決定には、目的と、それに紐づいた個々の判断があります。目的は、何を作りたいか、何を「良い」とするか、という向かう先そのものを決めること。個々の判断は、出てきたものは「これでいい」か、どの案で進めるか、どう実現するか、という向かう先が決まったあとの判断です。この線で切り分けてみると、見方①が「人間に残る」と言っていたのは目的のほう、見方②が「もう渡せる」と示していたのは個々の判断のほう、と読み直せます。そう捉え直したとき、正面からぶつかって見えた二つの主張は、どちらも成り立つ余地が出てきます。前章で見たAIたちでさえ、「何を良しとするか」という物差しそのものは、人間が与えたものを使っていました。AlphaEvolveが成果を出せたのも、人間が速さや正しさを測る物差しを用意した、その範囲の中だったのです。
そして、あなたを疲れさせているのは、目的に紐づいた個々の判断のほうです。冒頭の「これでいい」「これは違う」を一日じゅう裁き続けるあの感覚は、ほとんどがこの個々の判断で、「そもそも何が欲しいか」という目的を決める回数は、実はそれほど多くありません。
だとすれば、やれることははっきりしています。「判断は人間の仕事だ」と個々の判断まで全部を抱え込むのをやめて、渡せるものから少しずつAIに渡していくことです。「何が欲しいか」という目的だけを手元に残せたとき、人はようやく楽になれるはずで、どこまで渡せるのかは、正直まだ誰にも分かりません。それでも、人間に残すものが目的の一点に近づくほど、冒頭のあの疲れは少しずつ引いていくのだと思います。
データ分析でいうと ― 残るのは「問い」
この切り分けは、データ分析の仕事にそのまま重なります。分析の中身は、「何を知りたいのか」という問いを立てることと、その問いに「どう答えを出すか」という個々の判断に分かれます。後者は、どのテーブルをどう結合するか、どんな集計や可視化にするか、外れ値をどう扱うか、出てきた数字は「これでいい」か――数えきれない小さな判断の積み重ねです。
このうち、答えを出す側の判断は、これから少しずつagentへ渡っていくのだと思います。SQLを書く、集計する、グラフにする、出てきた結果の妥当性をいったん見る。どれも「良し悪しを測れる」作業で、見方②やAlphaEvolveの話がそのまま当てはまります。逆にいえば、何を「良い分析」とするかという物差しを人間が渡さないかぎり、agentはどこにも進めません。
最後まで自分の手元に残るのは、「そもそも何を知りたいのか」、そして「その答えを次のどんな判断に使うのか」という問いのほうです。分析でいちばん消耗するのも、たいていは答えを出す側の細かい判断で、問いそのものを立て直す回数は、実はそれほど多くありません。だとすれば、ここでやれることも同じです。答えを出す判断は渡していき、問いを立てるほうに時間を残す。それだけで、分析の手触りはずいぶん軽くなるはずです。
参考文献
The Orchestrator — Naming the successor to the knowledge worker | Nova Spivack — "Compute is becoming abundant. Judgment is becoming scarce." / "the organ that makes the output mean something"
Your future job will be to keep AI on task | Noah Smith (Noahpinion) — 人間の比較優位は「何が欲しいかを知ること」、作る作業から検証する作業へ
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena | Zheng et al., NeurIPS 2023 — 強いLLMを審査員に使う、GPT-4判定が人間と80%超一致(位置・冗長さ・自己びいきのバイアスも報告)
No Free Labels: Limitations of LLM-as-a-Judge Without Human Grounding | arXiv:2503.05061, 2025 — 人間の手本がないと一致率が落ち、自己びいきが強まる。人間によるグラウンディングは依然不可欠
τ-bench / τ²-bench | Sierra Research — ルール順守でツールを操作するcustomer-service agentのベンチマーク。新しいモデルでは小売の単発成功率が8割超(top model 84.7%)に達する一方、当初版ではgpt-4oが小売タスクの半分も通せずpass^8<25%とreliabilityが大きく低下。arXiv:2406.12045 / 2506.07982
Constitutional AI: Harmlessness from AI Feedback | Anthropic, 2022 — "enlist their help to supervise other AIs"、人間の評価をAI評価(RLAIF)で置き換える、scalable oversight
How we built our multi-agent research system | Anthropic, 2025 — lead agentが統括・分配・統合するorchestrator-worker型(通常チャットの約15倍トークン)
Automated Design of Agentic Systems | Hu, Lu, Clune(ICLR 2025) — meta agentがコードで新しいagentを生成、arXiv:2408.08435
The Darwin Gödel Machine | Sakana AI, 2025 — 自分のコードを書き換える自己改善coding agent、SWE-bench 20.0%→50.0%(1実行 約2週間/$22k、arXiv:2505.22954)
AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms | Google DeepMind, 2025 — 本番投入。データセンター計算資源を平均0.7%回収、Gemini学習カーネル23%高速化(学習時間1%短縮)、4×4複素行列積を48乗算でStrassen以来56年ぶり更新。限界は「自動評価器を作れる問題に限る」こと(arXiv:2506.13131)
Decision fatigue | Wikipedia — 決め続けると判断の質が落ちうるとされる現象(パロール審査の研究などで観察。「1日3.5万の決定」という数字は俗説で、査読研究の裏付けはないため本文では用いない)