Contents
Databricksは2026年6月15日〜18日、サンフランシスコで開催されたData + AI Summit 2026で、Genie One、Agent Bricks、Lakeflow、Lakebaseを基盤にしたLTAP、Lakehouse//RT、Unity AI Gateway、CustomerLake、Panther買収などを発表しました。
ここでは、2026年6月19日時点で確認できる公式発表を中心に、外部メディアやコミュニティで注目されていた論点、まだ確認が必要な点を分けて整理します。Databricksの発表は数が多いため、プレスリリースの順番をそのまま追うよりも、読者が後から確認しやすいカテゴリで並べています。
時間がない人向けの要約
今回の発表を一言でいうと、Databricksが「AIエージェントが企業データを使って仕事をするための土台」を広くそろえに来た、という内容です。業務ユーザー向けにはGenie One、開発者向けにはAgent Bricks、データ基盤・データエンジニアリング側にはLakeflow、Lakebaseを基盤にしたLTAPとLakehouse//RT、運用・統制側にはUnity AI GatewayやLakewatchが並びます。
すぐ押さえるなら、次の5点です。
Genie Oneは、SlackやTeamsなど業務ツールも含めて、企業データに基づくAI同僚を目指す発表。
Lakeflowは、取り込み、変換、オーケストレーションをUnity Catalogの下でまとめ、データパイプラインをAIで作り、運用する方向の発表。
LTAPとLakehouse//RTは、運用データ、分析、リアルタイムクエリの間にあるデータコピーやパイプラインを減らす方向の発表。
Unity AI Gateway、Unity Catalog、Lakewatchは、AIエージェントの権限、コスト、監査、セキュリティを管理するための発表。
ただし、提供時期、ベータ範囲、実データでの精度、買収後の統合はまだ確認が必要。
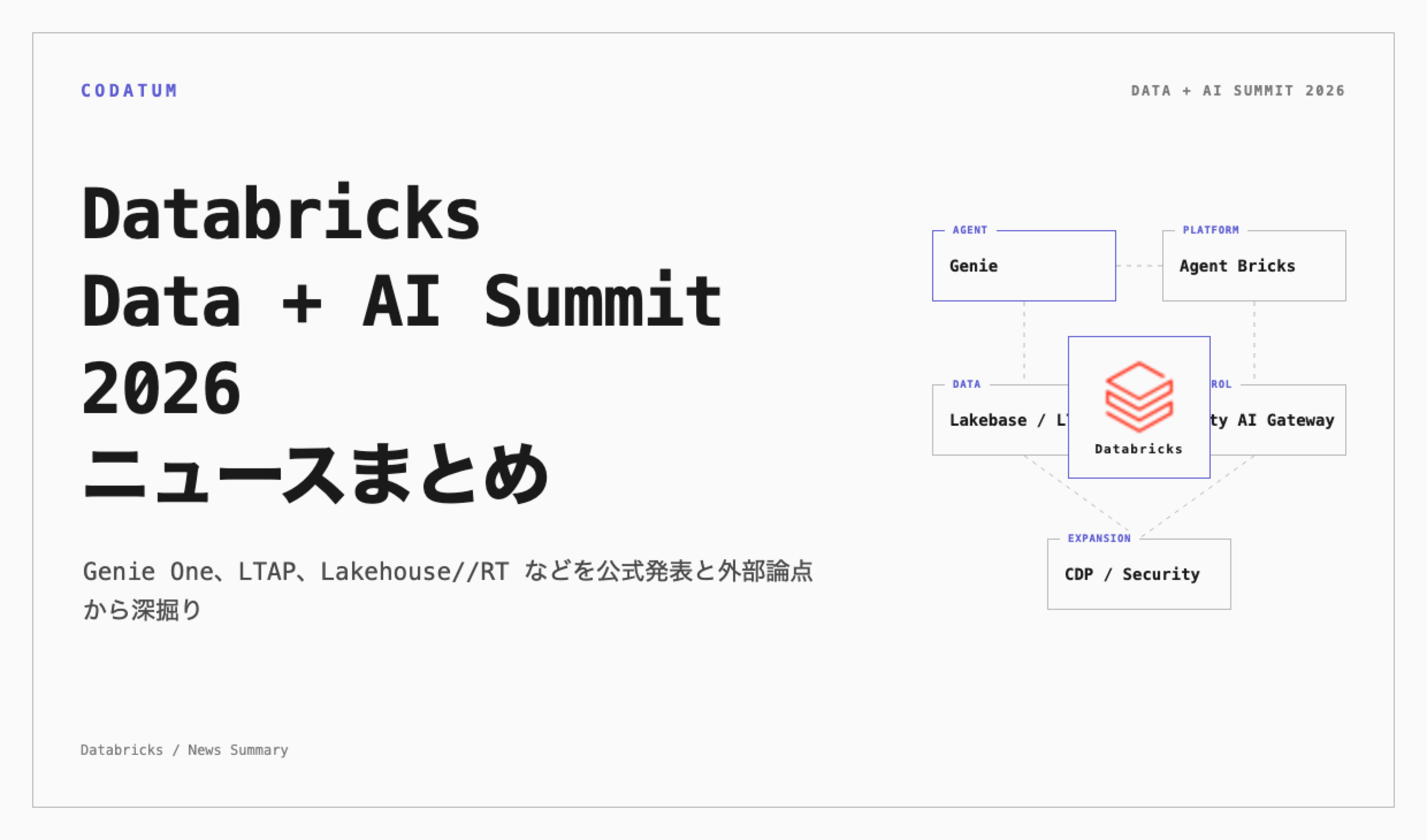
発表の全体像
今回の発表は、大きく見ると「AIエージェントが企業データを使って動くための土台」を広げる内容でした。Databricksは、業務ユーザー向けのAI体験、その下にあるデータ、業務文脈、低レイテンシのクエリ、ガバナンス、セキュリティ、共有までをまとめて発表しています。
主なカテゴリは次の通りです。
業務ユーザー向けエージェント: Genie One、Genie Agents、Genie App Builder
データ / ML チーム向けエージェント: Genie Code、Genie ZeroOps
開発者向けエージェント基盤: Agent Bricks、Omnigent、管理メモリ、サンドボックス
データエンジニアリング: Lakeflow Designer、Lakeflow Connect、Zerobus Ingest、Spark Declarative PipelinesのReal-Time Mode
データ基盤: Lakebaseを基盤にしたLTAP、Lakehouse//RT、Reyden
ガバナンス / 制御: Unity AI Gateway、Unity Catalog、Governance Hub、OpenSharing
業務カテゴリへの拡張: CustomerLake
セキュリティ: Lakewatch、Panther 買収
公式基調講演では、Databricks CEOのAli Ghodsi氏が「AIが企業で機能するには、文脈、制御、費用、選択肢が必要」という整理を置き、その後の発表もこの軸に沿って展開されました。公式YouTubeでは、Day 1 基調講演の10:12付近からこの整理、38:50付近からGenie Ontology、43:16付近からGenie One、2:47:45付近からLTAPが確認できます。
Genie One と Genie: 業務ユーザー向けの AI 同僚
公式発表では、Genie Oneは、業務チームが実際の企業データに基づいて仕事を自動化・調整するための自律的に動くAI同僚と説明されています。従来のGenieがDatabricks内の対話型分析に寄っていたのに対し、Genie OneはDatabricks内外の構造化 / 非構造化データ、Slack、Teams、Google Drive、Jira、Confluence、SharePoint、MCPツールなどをまたいで使う想定です。
Genie Oneの中心にあるのがGenie Ontologyです。Databricksはこれを、テーブル、クエリ、ダッシュボード、パイプライン、接続済みアプリなどから業務文脈を抽出し、指標定義、業務用語、チーム、データソースの関係を整理する文脈レイヤーと説明しています。公式ブログでは、PageRankに似た考え方で情報源の信頼度を評価し、権限のある情報だけを使って回答する、とされています。

同時に、Genie の周辺機能も広がりました。
Genie Agents: Genieの会話やGenie Spacesから、情報源、指示、ふるまいを引き継ぐ再利用可能なエージェントを作る機能。
Genie App Builder: 業務文脈からガバナンスされたアプリの構築計画とプレビューを生成する環境。非公開プレビュー予定。
Genie Code: データエンジニアリング、ML、分析ワークフローを支援する技術者向けエージェント。一般提供済み。
Genie ZeroOps: パイプライン、ジョブ、テーブル、MLモデルなどを監視し、調査し、修正案を出すバックグラウンドエージェント。非公開プレビュー予定。
提供状況も確認しておきたいところです。公式プレスリリースでは、Genie One、Genie Agents、Genie Codeは一般提供、Genie App BuilderとGenie ZeroOpsはSummit後に非公開プレビューとされています。Genieは座席数ベースの料金体系ではなく、ユーザーごとに月$10分の無料枠があり、その後は利用量に応じた課金になると説明されています。Databricksドキュメントでは、Genie製品群が2026年7月6日から従量課金モデルに移るとも記載されています。
外部メディアでは、Genie One は「既存の AIコパイロットが業務文脈を十分に持てない」という Databricks の問題提起とセットで取り上げられていました。SiliconANGLEは、営業、マーケティング、財務などでは、業務文脈が文書、チケット、会議、人の知識に散らばっており、Genie Ontology がそこを埋めるという説明を紹介しています。
ここは導入後の検証が必要な領域でもあります。公式ベンチマークはありますが、企業ごとに揺れる用語、権限、情報の鮮度、情報源の信頼度をどこまで正確に扱えるかは、実際の利用環境で評価されるべきです。
Agent Bricks: 開発者向けエージェント基盤
Agent Bricksは、2025年のSummitで発表されたエージェント構築基盤を、2026年にはより広い開発者向けエージェント基盤として拡張したものです。公式ブログでは、これまでに10万以上のエージェントが作られ、年間1000兆トークン以上を処理していると説明されています。
今回の Agent Bricks の説明で中心になっているのは、選択肢、文脈、制御です。
選択肢: OpenAI、Anthropic、Gemini、Qwen、Kimi、Grok など複数のモデルを使い分ける。
文脈: Genie Ontology、Databricks Agent Tools、MCP、Document Intelligence、管理メモリを使い、エージェントが必要な文脈にアクセスする。
制御: Unity AI Gateway、Unity Catalog、エージェントの実行記録、Lakewatch、文脈に応じたポリシーで、アクセス、コスト、監視、セキュリティを管理する。
エージェント実行基盤についても、LangGraph、Agno、CrewAI、Claude Code SDK、OpenAI Agents SDKなどをサポートし、Databricks Appsにデプロイできるとされています。オープンソースのメタ実行基盤として発表されたOmnigentの管理版、Omnigent on Databricksもベータとして紹介されています。
外部記事では、Agent Bricks は「エージェントを作ること」よりも、「エージェントを運用するための周辺基盤」を Databricks 側が引き受ける発表として読まれていました。SiliconANGLE の Day 2まとめでは、Omnigent と Unity AI Gateway を、エージェントの組み合わせ、共有、監督、コスト管理の文脈で整理しています。
Lakeflow: AI時代のデータエンジニアリング基盤
もうひとつ追加で押さえておきたいのが Lakeflow です。DatabricksはLakeflowを、データの取り込み、変換、オーケストレーションをUnity Catalogの下でまとめるデータエンジニアリング基盤として説明しています。今回の発表では、Lakeflow Designer、Lakeflow Connect、Zerobus Ingest、Spark Declarative PipelinesのReal-Time Mode、Lakeflow Jobsなどが並びました。
特に重要なのは、Genie CodeやGenie ZeroOpsとつながる点です。パイプラインを自然言語やビジュアル操作で作るだけでなく、障害検知、原因分析、修正案の生成までAI Agentに寄せる方向が示されています。100以上のマネージドコネクタ、Kafka互換API、OpenTelemetry対応、Spark Declarative Pipelinesの5ミリ秒級レイテンシなど、Lakehouse//RTやLTAPとは別の層で「データをAIが使える状態に集め、動かし続ける」発表として見ると整理しやすいです。
LTAP: Lakebaseを基盤に運用データと分析を近づける発表
今回の中でも技術的な注目が大きかったのが LTAP です。LTAP は Lake Transactional/Analytical Processing の略で、Databricks は「OLTP、OLAP、ストリーミング、運用データをレイク上の単一コピーに寄せるアーキテクチャ」と説明しています。
公式発表では、LTAP は Lakebase を基盤にします。Lakebase はサーバーレスPostgresをDatabricksプラットフォームに組み込む運用データベース層で、2026年の発表では、Lakebaseの新機能とLTAPアーキテクチャの関係が強調されました。LTAPではLakebaseがUnity Catalog上のDelta / Icebergなどのオープンフォーマットにデータを置き、Lakehouse側の分析エンジンと同じガバナンスされたデータを扱う、という説明です。
ポイントは、HTAPのように1つのエンジンでトランザクション処理と分析処理の負荷をまとめる形ではないことです。Databricksは、ストレージ層を共有し、トランザクション処理エンジンと分析エンジンは分ける、と説明しています。公式発表では、Lakebaseは数千の顧客に使われ、1日あたり1200万回のデータベース起動を処理しているとも説明されています。
ただし、LTAPの提供時期は「Lakebaseの一部として近日提供」です。ここは Lakebase そのものの一般提供状況と混同しない方がよいです。記事執筆時点では、LTAP の詳細な 一般提供日程は公式発表からは確認できませんでした。
外部メディアはここをかなり大きく扱っています。VentureBeatは、LTAPを「HTAPではなくストレージ層の統合」と整理し、Postgresはトランザクション処理エンジン、Spark / Lakehouseは分析エンジンのまま、下位のストレージを共有する構成だと説明しています。InfoWorldも、パイプライン削減、ガバナンスの単純化、開発者体験の改善を期待点として挙げています。
同時に、外部記事では慎重な見方も出ています。実運用でのコミットからクエリ可能になるまでの遅延、トランザクション処理負荷の信頼性、OLTP性能、見えない変換や同期の有無は、今後の検証ポイントです。Hacker Newsのスレッドでも、検索結果から確認できる範囲では、列指向ストレージとOLTP性能の関係に関心が向いていました。
Lakehouse//RT / Reyden: リアルタイムクエリをレイクハウスで扱う
Lakehouse//RTは、Delta Lake / Apache Icebergテーブルを直接クエリするリアルタイムレイクハウスの発表です。新しい計算エンジンであるReydenを使い、別の配信層、データコピー、同期やCDCパイプラインを持たずに、Unity Catalogのガバナンスの内側で低レイテンシのクエリを実行する、と説明されています。

公式発表では、Lakehouse//RTはベータです。標準ベンチマークでは 12,000 QPSで 100ミリ秒未満の遅延、小規模データセットで 10ミリ秒、顧客のプレビューでは最大 16倍の性能改善と説明されています。公式ブログでは、ベータは一部の読み取り専用負荷から始まり、2027 年 1 月まで 30%の導入割引も記載されています。
Lakehouse//RT と LTAP は似て見えますが、役割は違います。LTAPは運用系の書き込みと分析のストレージ層を近づける発表です。Lakehouse//RT は、既存のレイクハウス上のデータに対して低レイテンシの読み取りとクエリ配信を行う発表です。どちらも「データコピーを減らす」という方向は共通していますが、片方はトランザクション処理と分析処理のアーキテクチャ、もう片方はリアルタイム配信エンジンとして読むと整理しやすいです。
外部メディアでは、Lakehouse//RTはリアルタイム配信の構成やキャッシュ層を減らせる可能性として取り上げられていました。ただし、現時点ではベータであり、読み取り専用からの開始です。既存の専用の配信システムをすぐ置き換えられるかは、負荷、必要なレイテンシ、クエリの複雑さ、運用体制によって変わります。
Unity AI Gateway と Unity Catalog: エージェントのガバナンス
AIエージェントが業務データ、MCPサービス、モデル、コーディングツールに触れるほど、どのエージェントが何をできるのか、いくら使っているのか、どの操作を止めるべきかが重要になります。Databricksはこの領域でUnity AI Gatewayを前面に出しました。
公式ブログでは、Unity AI GatewayはUnity Catalogを基盤に、モデル、エージェント、MCPサービス、スキル、社内ツールの実行時のやり取りを管理する層だと説明されています。主な内容は次の通りです。
AI利用費の可視化、細かなコスト配賦、厳格な利用上限、スマートルーティング
モデル、MCPサービス、エージェント、スキルのUnity Catalogへの登録、発見、監査
文脈に応じたサービスポリシーによる許可、拒否、承認要求
個人情報の露出、プロンプトインジェクション、脱獄攻撃、危険な内容などへのガードレール
統合されたエージェント追跡とLakewatchでの調査
Omnigent on Databricks管理版のベータ提供
ドキュメントでは、Unity AI Gatewayは新しいAI Gatewayとしてベータと明記されています。AWS GovCloud / Azure Governmentは未対応とされているため、規制の厳しい環境での採用検討では確認が必要です。
セキュリティとコンプライアンス面では、Data + AI Summit 2026の公式ブログで、Automatic Identity Management、Context-Based Ingress、Private Network Gateway、Lakebase向けPrivate Link、HITRUST / ISMAP / GovCloud / FedRAMP High関連の拡張も説明されています。AI利用を広げるほど、ID管理、ネットワーク境界、規制対応がボトルネックになるため、Unity AI Gatewayだけでなく、こうした基盤側の更新もセットで見る必要があります。
Unity Catalog側でも、Data + AI Summit 2026の発表としてGovernance Hubの非公開プレビュー、Glossaryは近日プレビュー提供、Domainsの公開プレビュー、メトリクスの改善、外部リネージの一般提供、ABAC拡張、OpenSharingとの接続などが出ています。DatabricksはUnity Catalogを、エージェントが参照する業務文脈と権限の土台としても扱っています。
OpenSharing: データからAI資産へ広がる共有
OpenSharing は、Delta Sharing の発展として発表されたオープンプロトコルです。Databricks の発表と Linux Foundation の発表の両方で、Linux Foundationがホストする、ベンダー中立、エージェントスキル、AIモデル、非構造化データ、Iceberg受信者、オンプレミスやプライベートクラウド上の資産への対応が説明されています。
OpenSharing は 6 月 10 日の発表で、Summit 本編より少し前に出ていますが、Unity Catalog / 共有 / エージェントスキルの文脈では今回の発表群とつながります。GitHubリポジトリも公開されています。
ただし、ここも成熟度の確認が必要です。READMEでは、テーブル、ボリューム、モデル、エージェントスキルなどが扱われていますが、実際にどの資産タイプがどの程度本番利用できる状態なのか、どのクライアント / サーバー実装がどこまで対応しているのかは、今後の採用状況を見た方がよさそうです。
CustomerLake: マーケティング / CDP領域への拡張
CustomerLake は、Databricksがマーケティング / CDP領域に入る発表です。公式発表では、Customer 360、ID統合、オーディエンス作成、キャンペーン自動化、配信先連携、パーソナライズをDatabricksレイクハウス上に置く自律型の顧客データプラットフォームと説明されています。
中心になるのは Profile Agents と Campaign Agents です。Profile Agentsは生の顧客データから Customer 360プロファイルを作ることを支援し、Campaign Agentsはガバナンスされた顧客文脈を使って、オーディエンス、次に取るべき施策、配信先連携、最適化を支援する、という説明です。
CustomerLakeは非公開プレビューです。Adobe、Meta、Braze、The Trade Desk、LiveRamp、Twilio などのパートナーエコシステムも紹介されていますが、既存 CDP、CRM、マーケティング自動化、IDグラフとどのように棲み分けるのか、実際の移行コストや運用負荷はまだ確認が必要です。
外部メディアでは、CustomerLake は Databricksが汎用データプラットフォームから業務カテゴリに踏み込む例として見られていました。SiliconANGLE の Day 2まとめでは、エージェントが買い手や顧客との接点に関わることでマーケティング業務が変わる、という文脈で紹介されています。
Panther 買収と Lakewatch: セキュリティレイクハウス
Databricks は Panther を買収する意向も発表しました。Panther は AI SOCプラットフォームと説明され、100以上の連携、コードによる検知定義、自律型SOCワークフローを持つとされています。
Databricks はこれを Lakewatch / セキュリティレイクハウス構想の強化として位置づけています。Lakewatch は セキュリティ、IT、業務データをガバナンスされたレイクハウスに統合し、自律的な検知と対応を支援するという説明です。Unity AI Gatewayの実行記録を Lakewatch で調査する、という ガバナンス / セキュリティの接続も公式ブログで触れられています。
Reuters 配信の CNA 記事では、Databricks が Panther Labs を買収することで サイバーセキュリティ事業を深め、CrowdStrike や Cisco の Splunk など 既存のセキュリティ管理企業と競合する方向に進むと整理されています。Panther は 2021 年の Series B 後に 14億ドルの評価額とされ、Anthropicが顧客として言及されています。
ただし、買収は通常の買収完了条件や規制当局の承認が前提です。買収条件、買収完了時期、Lakewatch への統合ロードマップ、既存Panther顧客への影響は、記事執筆時点では公式情報だけでは分かりません。
外部メディア、Hacker News、Databricks Communityが見ていた論点
外部メディアが強く見ていたのは、Databricks の発表を「自律型AIのためのデータアーキテクチャ」として読む視点でした。特に VentureBeat、InfoWorld、SiliconANGLE は、LTAP / Lakehouse//RT を、ETL、CDC、リアルタイム配信層、ガバナンスの分断を減らす試みとして取り上げています。
同時に、外部記事は全体的に、実運用での検証も必要だと見ています。LTAP については、単一ストレージ層の実装、コミットからクエリ可能になるまでの遅延、OLTP性能、信頼性が焦点です。Lakehouse//RT については、ベータであること、読み取り専用負荷からの開始であること、公式ベンチマークと プレビュー顧客のコメントをどう評価するかが論点です。
Genie One / Genie Ontologyでは、業務文脈の分断をどう解くかが中心でした。公式の説明は明確ですが、外部での独立した評価はまだ少なく、導入企業ごとの実データ、権限、意味定義での検証が必要です。
最終日後の追加記事では、SiliconANGLEのまとめが、今回のSummitを「実験段階のAIから、本番利用できるAI基盤への移行」として整理しています。個別機能の勝ち負けよりも、データ、ガバナンス、コスト、セキュリティを統合して、企業がAIを本番に載せられるかが論点になっていました。
Hacker Newsでは、LTAPの発表スレッドで、かなり具体的な論点が出ています。まず、「自律型AI時代のデータ基盤」という打ち出しに対して、AIとの結びつけがPR的で技術説明を曇らせている、という懐疑がありました。一方で、実際にChatGPTとDatabricksをまたいで業務データを扱っている読者からは、「Databricks内のPostgres」として使えて、アプリや業務チャット層との間のETLを減らせるなら意味がある、という見方も出ています。
技術的な疑問は、LTAPの中でデータが最終的にどの形式で保存されるのか、列指向ならOLTP性能はどうなるのか、Postgresと分析エンジンの間に本当にデータ移動や変換がないのか、という点に集まっています。別のLakebaseアーキテクチャのスレッドでは、Databricks / Neon関係者も参加し、ページ再構成、S3上の古いデータ、読み取りレプリカ、HAへの影響などが議論されています。さらにNeon買収時のスレッドでは、Neonの独立性、OSS性、価格、買収後の扱いへの不安と、OLTPはPostgres、OLAPはレイクハウス側が担う構成への期待が並んでいました。
Lakebaseを実際に触った人のコメントでは、UIからの利用体験には期待がある一方で、APIのエラーメッセージ、未文書化のレート制限、テーブル再作成時の不安定さ、価格に対する納得感など、プロダクトの成熟度に関する懸念も出ていました。これはLTAPそのものへの評価ではありませんが、LTAPの基盤になるLakebaseを本番に入れるときの確認ポイントとしては重要です。
ここでいうコミュニティは、主にHacker NewsとDatabricks Communityです。Redditについては、発表そのものを大きく議論する公開スレッドは確認できませんでした。ただし、r/databricksへの投稿がSummitでの会話につながった事例がDatabricks Communityに掲載されています。
この事例は、Grocery Data IntelligenceというDatabricks Free Editionアプリに対して、r/databricksでの投稿をきっかけに、Summitの場でアクションフローの改善、アーキテクチャの明確化、Lakebaseによるダッシュボード高速化、セマンティックレイヤー / UC Metric Views、Genie Code、Ask Data体験へのフィードバックが寄せられた、という内容です。発表への一般的な賛否ではありませんが、今回の発表で強調された「文脈を持つAI」「Lakebase」「セマンティックレイヤー」が、Databricks利用者の実装相談として扱われている例です。
Databricks Communityでは、Day 2の参加レポートで、Ali Ghodsi氏の「Context、Cost、Control、Choice」という整理が印象に残った、という反応が出ていました。特に、Genie OntologyやGenie Oneへの反応は「AIが賢いか」よりも「企業文脈を理解できるか」に寄っており、今回の発表全体の受け止め方をよく表しています。
日本語圏でも、noteやZennで技術的な読み解きが増えています。たとえば Day 2基調講演を技術スタックで整理したnote では、Lakeflow / Lakehouse//RT / Lakebase / LTAP をデータ基盤、Genie Ontology / Genie One / Genie Agents をコンテキスト層として整理しています。また ZennのLTAP / Lakehouse//RT解説 では、HTAPとの違いを「クエリエンジンを一本化するのではなく、下のストレージを一本化する」と捉えており、日本語コミュニティでも単なるニュース転載ではなく、アーキテクチャの意味を読み解く方向に議論が進み始めています。
なお、Databricks Communityの最終日投稿を見る限り、6月18日はクロージングキーノート、最終セッション、Expoの締めが中心でした。少なくとも確認できる範囲では、この記事の軸を変えるほどの新しい大型製品発表は追加されていません。
まだ確認が必要な点
今回の発表は広いので、特に以下は今後の確認が必要です。
LTAP の具体的な提供時期、一般提供時期、実運用での遅延と信頼性。
Lakebase 自体の状態と LTAP の状態の切り分け。
Lakehouse//RTのベータ対象の負荷、読み取り専用以外の対応、一般提供予定、導入割引後の価格。
Lakeflow Designer、Genie ZeroOps、Spark Declarative PipelinesのReal-Time Modeが、実運用の複雑なデータパイプラインでどこまで機能するか。
Genie App Builder / Genie ZeroOps の 非公開プレビュー 開始時期、対象顧客、価格。
Genie Ontologyの企業内文脈の抽出が、実際の企業データでどの程度正確に機能するか。
Unity AI Gateway の機能ごとのリージョン / クラウド対応とベータから一般提供 への道筋。
CustomerLake が既存 CDP / マーケティング技術スタックをどこまで置き換えられるか。
Panther買収の完了、統合ロードマップ、既存製品への影響。
OpenSharingのエージェントスキル / AIモデル / 非構造化データ共有の実装成熟度と エコシステムでの採用状況。
CodatumでDatabricksを使うには
CodatumはDatabricksと連携できます。接続にはDatabricks SQL Warehouseを使い、必要な情報を設定すれば数分で接続できます。具体的な設定手順はCodatumのDatabricks接続ガイドにまとまっているので、ここでは組み合わせるとできることを簡単に整理します。
Databricksはデータを蓄積し、権限を管理し、計算する基盤です。Codatumと組み合わせると、その上のデータをノートブックやレポートで扱い、SQL、チャート、解釈をまとめて残せます。長いSQLをブロックに分けて組み立てたり、テーブル説明や保存済みクエリを業務文脈として足したり、必要な結果だけをSlack、Email、社内Wikiなどで共有する、といった使い方ができます。
Databricks側のガバナンスや計算基盤はそのまま使いながら、Codatum側で分析の過程と共有先を整理できます。Databricksで扱えるデータやワークロードが広がるほど、Codatumで分析し、レポート化できる対象も増えていきます。
最後に
今回の発表は、Databricksがレイクハウスの上に、データエンジニアリング、データベース、リアルタイム処理、AIエージェント、共有、セキュリティまで広げようとしていることを示すものでした。一方で、LTAP、Lakehouse//RT、Lakeflow、Genie系の新機能などは、提供時期や実運用での性能をこれから確認する段階でもあります。
Codatumのような外部の分析ワークスペースと組み合わせると、Databricksで作ったデータ基盤を、SQL、ノートブック、レポート、AI Agentの文脈として使いやすくできます。Databricks上のデータをためるだけでなく、チームで読み、分析し、共有するところまで含めて設計するのが、この発表を実務で見るときのポイントになりそうです。