Contents
自然言語で質問すると、Agent がテーブルを探し、SQL を書き、必要なら Python で後処理し、最後に要約まで返します。こうしたデータ分析の Agent は、すでに BI やデータ基盤の製品に組み込まれ始めていて、手元で動かせるところまで来ています。
ただし実務で怖いのは、Agent が間違えることそのものより、間違っている答えが正しそうに見えることです。SQL は動いていて、グラフも出ていて、説明文も自然に読めてしまうので、どこを疑えばいいのかがかえって見えにくくなります。
SQL が動くことは、分析が正しいための必要条件ではあっても、十分条件ではありません。どの指標を計算するのか、どの粒度で見るのか、どの除外条件を入れるのか、途中結果をどう検証するのか。ここを外すと、クエリは成功しても、分析としては間違います。
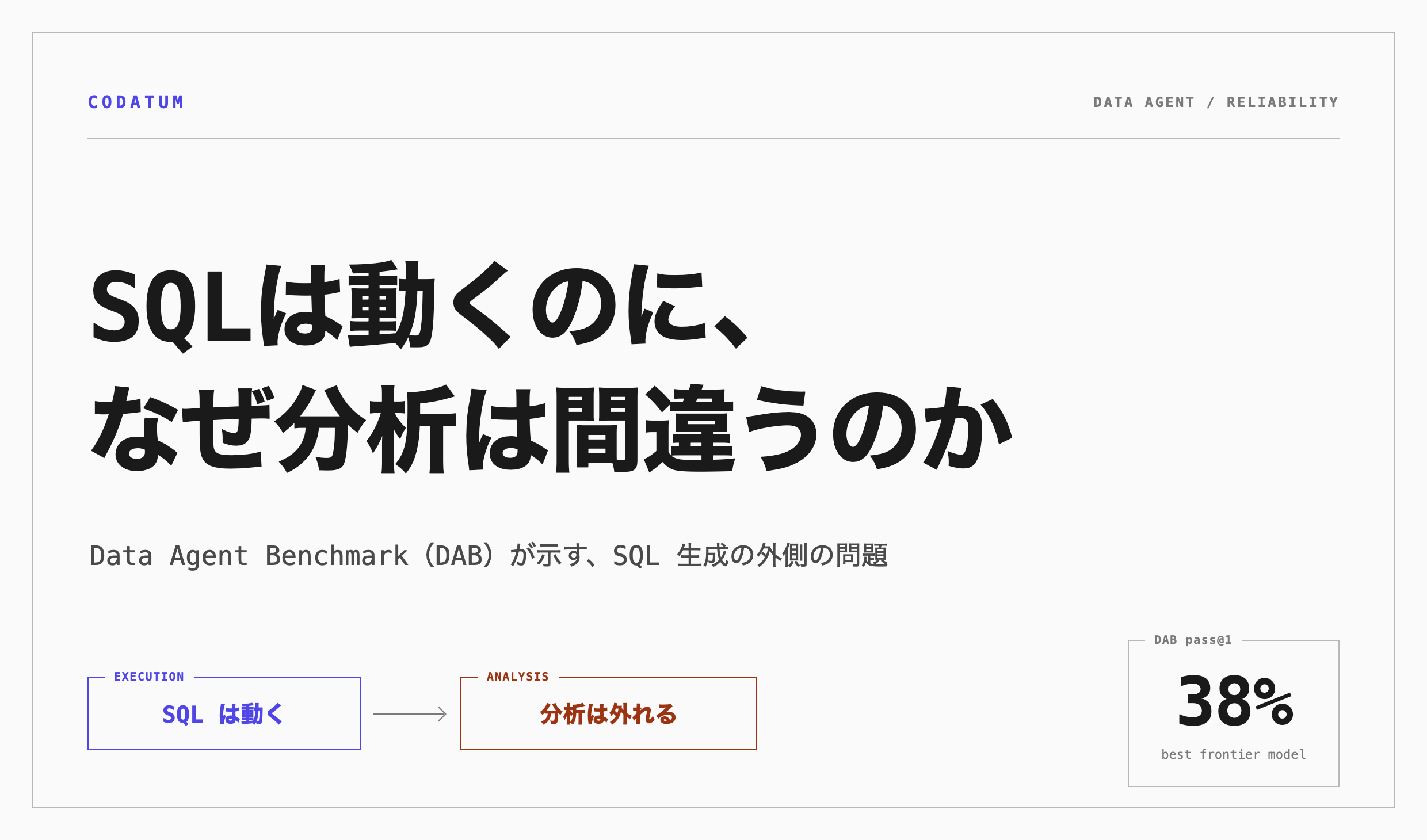
UC Berkeley EPIC Data Lab と Hasura PromptQL が公開した Data Agent Benchmark(DAB)は、データ分析を任せる Agent がどこまで正しく答えられるかを測った論文です。その標準的な評価では、最も成績の良かった最新モデルでも pass@1 は 38% でした。pass@1 とは、各問題を 1 回だけ試したときに正解できた割合のことです。最初の一発で正しい答えに到達できたのは、4 割弱だったということになります。
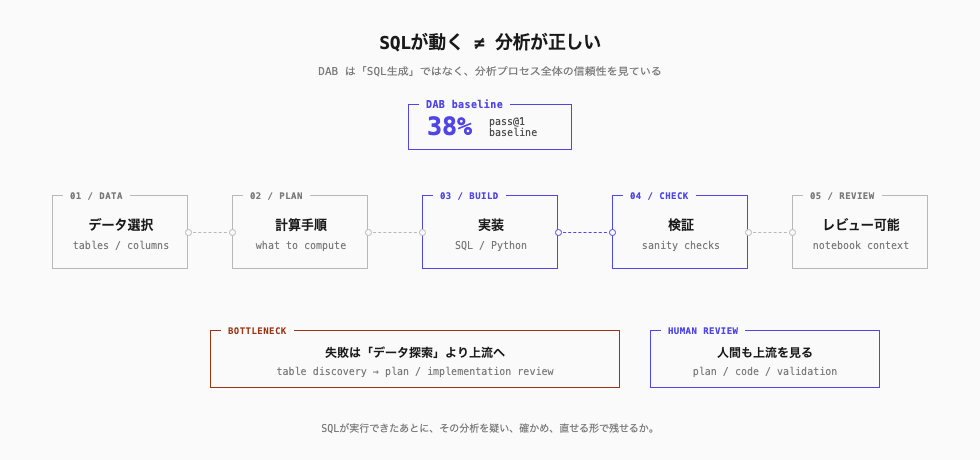
Data Agent の問題は、Text-to-SQL の精度だけではなく、問い、計画、実装、検証を含む分析プロセス全体の信頼性として見る必要があります。
この数字だけを見ると、「AI にデータ分析を任せるのはまだ無理」という結論に進みたくなります。けれど、DAB が面白いのは正答率そのものよりも、どこで失敗しているかを分解している点です。この記事では 38% を性能競争の数字としてではなく、SQL が動いても分析が間違う理由を考えるための補助線として読みます。
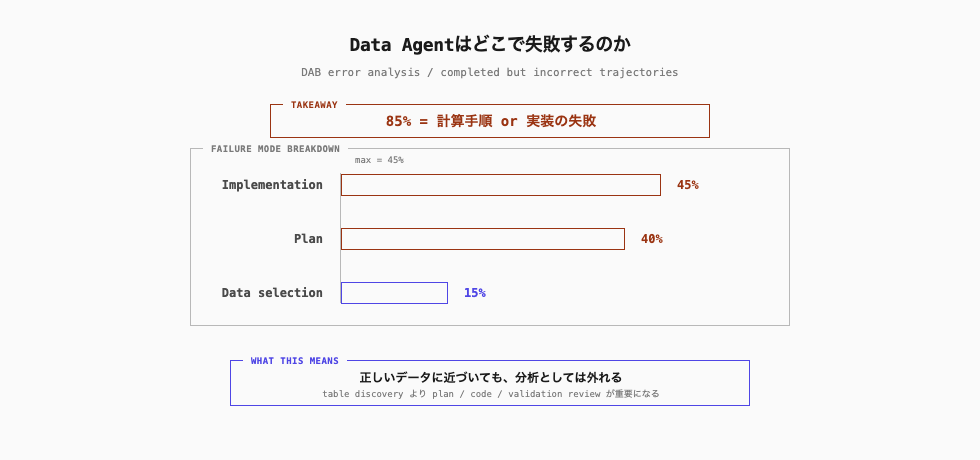
ここで見えてくるのは、問題が単に SQL 生成精度の低さに閉じないということです。DAB の失敗分析では、誤答の 85% が計画と実装の誤り、つまり計算の組み立てと実装の失敗に集中していました。反対に、間違ったデータソースを選ぶ誤りは 15% に留まっています。
Data Agent は、正しいテーブルやカラムにたどり着けないから失敗しているだけではありません。多くの場合、何を計算すべきかを決めるところ、あるいは決めた計算を正しく実装するところで崩れています。ここに、SQL 生成の精度だけでは見えない論点があります。
38% が示す、SQL 生成の外側の問題
DAB は、Data Agent を Text-to-SQL(自然言語の質問を SQL に変換する技術)より広い範囲で評価するためのベンチマークです。
従来の Text-to-SQL ベンチマークは、自然言語の質問を 1 本の SQL に変換できるかを主に見ます。これは重要ですが、実務のデータ分析はそれだけでは終わりません。複数のデータベースをまたぎ、ID の形式違いを直し、テキスト列から値を抽出し、業務固有の定義を適用し、必要なら Python で後処理します。DAB は、こうした実務に近い複雑さを含めて Data Agent を評価しようとしています。
ベンチマークは、54 個の問題、12 のデータセット、9 つの業務領域、4 種類のデータベース(PostgreSQL、MongoDB、SQLite、DuckDB)で構成されています。すべての問題が複数 DB をまたいだ統合を必要とします。さらに、26 問は形式の揃っていない結合キー(join key)を含み、47 問は整っていないテキストから必要な値を取り出す必要があり、30 問では業務知識(domain knowledge)も求められます。
DAB は、自然言語を 1 本の SQL に変換できるかだけではなく、複数 DB、形式の揃っていない結合キー、テキスト抽出、業務ロジックをまたいで分析できるかを見ています。

この条件で、論文では GPT-5.2、GPT-5-mini、Gemini-3-Pro、Gemini-2.5-Flash、Kimi-K2 といった最新モデルを ReAct 型の Agent として評価しています。ReAct は、Agent が「考える → ツールを実行する → 結果を見てまた考える」を繰り返しながら答えにたどり着く、標準的な動かし方です。各問題を 50 回ずつ試し、pass@1(1 回で正解できた割合)と pass@50(50 回のうち 1 回でも正解できた割合)を測っています。
結果は厳しいものでした。最も成績の良かった Gemini-3-Pro でも pass@1 は 38% にとどまり、pass@50 でも 69% を超えませんでした。特許データを使った問題群にいたっては、どのモデルも 50 回すべてで不正解だったと報告されています。
ただし、この数字は読み方に注意が必要です。
これは「すべての AI データ分析が 38% しか当たらない」という意味ではありません。DAB は、あえて実務に近い難しさを詰め込んだベンチマークです。また、公開されているスコア表は更新され続けており、論文の後に投稿された専用の Agent では 60% 台の pass@1 も出ています。この記事では、38% を「DAB 論文時点の標準的な構成が示した出発点」として扱います。
それでも、38% という数字は軽く扱えません。モデルの優劣を決めるためではなく、Data Agent を「SQL を生成する機能」として見るだけでは足りないことを示しているからです。
Text-to-SQL だけでは足りない
Data Agent の失敗を Text-to-SQL の問題として見ると、論点は「SQL を正しく書けるか」に寄ります。SQL はもちろん重要で、結合(join)の条件を間違える、絞り込みをかけ忘れる、期間の指定を取り違える、集計の粒度を間違えるといった失敗は、実務でもよく起きます。
ただ、DAB が見せているのは、SQL が失敗のすべてではないということです。
DAB の問題は、単に SELECT ... GROUP BY ... を書けば終わるものではありません。たとえば、ある情報が PostgreSQL と SQLite に分かれていることがあります。結合キーは bid_123 と bref_123 のように形式が違い、必要な値も専用の列ではなく、説明文の列(details column)に自然文で埋め込まれています。さらに、株式、医療、CRM、特許といった業務知識も必要になります。
このとき Agent は、次のような一連の判断をしなければなりません。
どのデータベースを見るべきか
どのテーブルとカラムが関係しているか
ID の形式違いをどう正規化するか
自然文からどの値をどう抽出するか
どの指標定義や業務ルールを使うか
SQL と Python をどう組み合わせるか
出てきた結果が妥当かどうかをどう確かめるか
ここまで来ると、問題は SQL 生成ではなく、分析プロセス全体の信頼性になります。SQL が動いたあとに、分析として正しいかを判断できるかどうかが問われます。
焦点は「正しい SQL を 1 本出せるか」ではなく、「問いを分解し、必要なデータを見つけ、計算手順を組み、実装し、結果を検証できるか」にあります。DAB は、この広いプロセスを見ています。
失敗の 85% は計画と実装にある
この見方を具体的にしてくれるのが、DAB の失敗分類です。論文では、最後まで回答したのに間違っていた試行(completed but incorrect)1,147 件を分析しています。その結果、最も多かったのは実装の誤り(incorrect implementation)で 45%、次が計画の誤り(incorrect plan)で 40%、データ選択の誤り(wrong data selection)は 15% でした。
計画の誤りは、そもそも解くべき計算手順を間違える失敗です。実装の誤りは、方針は近いものの、ID の正規化、抽出条件、集計粒度、後処理のどこかで実装を外す失敗です。
つまり、間違ったデータを見ていたケースよりも、正しいデータに近い場所まで来たうえで、計算の組み立てや実装を間違えたケースの方が多いことになります。
これは直感に反するかもしれません。Data Agent の難しさは、巨大なデータ基盤の中から正しいテーブルを見つけることだと思いがちだからです。もちろん、それも簡単ではありません。DAB でも、株式市場のデータのように 2,754 個のテーブルを持つケースでは、データ探索の難しさが表に出ます。
しかし、論文の takeaways はもう少し先にあります。
Agents typically select the right data, but fail at planning the computation or implementing it correctly.
正しいデータを選べることと、正しい分析ができることは別物だ、という指摘です。
実務でも同じことが起きます。テーブルは合っていて、カラムもだいたい合っていて、SQL も動いているのに、分析としては外れている場合があります。Data Agent の怖さは、この「正しそうに見える誤答」を作りやすいところにあるのです。
実務で起きる失敗
たとえば MRR(月次経常収益)を分析するとします。Agent が契約テーブルと請求テーブルを見つけ、月次売上を集計する SQL を書くところまでは、できるかもしれません。ただし、MRR には解約・ダウングレード・アップグレード・返金・通貨換算・無料トライアル・営業経由の契約など、チームごとに固有の扱いが入ります。どのタイミングで MRR に含めるのか。契約開始日なのか、請求日なのか、利用開始日なのか。ここを取り違えると、SQL は動いても MRR 分析としては間違います。
プロダクト分析でも、「activation rate(ユーザーが使い始めた割合)が下がった理由を調べて」と聞いたとき、Agent はイベントのテーブルを見つけてファネル(利用の各段階)を作るかもしれません。けれど、イベントの発火タイミング、user_id と workspace_id の違い、bot や社内ユーザーの除外、既存ユーザーと新規ユーザーの分離を誤ると、数字はきれいに見えても意味が変わります。
マーケティング分析では、リードの作成日と商談の作成日を混同するだけで、施策の評価が変わります。カスタマーサクセス(CS)の分析では、顧客単位で見るべきところを workspace 単位で集計すると、ヘルススコア(顧客の利用状況の健全度)の解釈がずれます。
これらは、単純な「SQL が書けるか」の問題ではありません。問いをどう分解し、どの粒度で見て、どの業務ルールを適用し、結果をどう検証するかの問題です。
そして、多くの場合、間違いは最終回答だけを見ても分かりません。途中の計画、SQL、集計結果、検証の有無を見て初めて分かります。
すべてを人間が見る設計は続かない
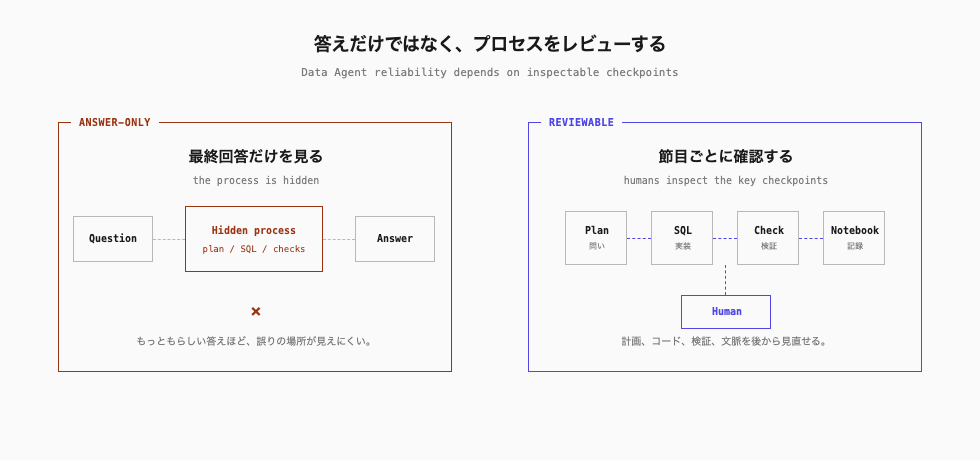
では、Agent の出力を人間がすべてレビューすればよいのでしょうか。
それも現実的ではありません。AI に作業を任せるほど、確認すべきものは増えます。SQL、グラフ、要約、示唆、次に投げる問い。すべてを人間が読み、すべてに「これは正しい」「これは違う」と判断を下していると、作業は減っても判断の疲れは残ります。
かといって任せきってしまうのも危なくて、特にデータ分析では、間違った答えが自然文で自信ありげに返ってくることがあります。SQL が動き、グラフが出て、もっともらしい示唆まで付いていると見た目の説得力が高いので、レビューの仕方そのものを設計しておく必要があります。
そのため、人間が見る対象も最終文面だけに閉じるわけにはいきません。
Agent がどう問いを分解したか
どの指標・テーブル・カラムを選んだか
SQL や Python が計画に合っているか
途中結果に簡単な妥当性チェックがあるか
最終結論が、業務上の定義や過去の判断と矛盾していないか
この節目を見られるなら、人間はすべての作業を抱え込まずに済みます。反対に、最終回答しか見えないなら、結局人間は裏側を推測し直すことになります。
Data Agent に必要なのは、自動化の強さだけではなく、レビューできる形で自動化されていることです。
Data Agent に必要な設計
DAB の数字を悲観材料として読むより、設計の論点として読む方が建設的です。
まず必要なのは、Agent が参照する文脈です。スキーマ、データの来歴(lineage)、指標の定義、過去のクエリ、分析メモ、業務ルール。これらがないと、Agent はデータベースにアクセスできても、何をどう計算すべきかを毎回その場で推測することになります。
ただし、文脈を増やせば解けるという話でもありません。DAB では、Agent が正しいデータソースを選べているケースも多く、それでも計画や実装で崩れています。つまり、必要なのは文脈だけではなく、計画と検証の仕組みです。
実務の Data Agent には、少なくとも次のような性質が要ります。
Agent の計画が人間に読めること
SQL、Python、グラフ、要約が同じ分析の文脈に残ること
指標やテーブルの意味を Agent が参照できること
過去の分析やチームの判断を再利用できること
結果に対して検証用のクエリや簡単な妥当性チェックを回せること
間違いを見つけたとき、次回以降の文脈や運用に反映できること
ここで問題にしているのは、単なるモデルの精度ではありません。信頼性、レビューのしやすさ、検証可能性です。
Data Agent を「SQL を書く人の代替」と見ているうちは精度の話に閉じてしまいますが、「分析プロセスを進めるシステム」として見ると、問い、計画、実装、検証、記録のどこを支えるかという論点に変わってきます。
Codatum としての見方
Codatum としては、この問題を「Agent の精度」だけではなく、「Agent が進めた分析を人間が検証できる形で残せるか」の問題として見ています。
データ分析では、答えそのものと同じくらい、そこに至る過程が重要です。どの問いから始めたのか。どのテーブルを見たのか。どの SQL を書いたのか。どのチャートを見て、どの仮説を捨て、どの結論に進んだのか。これが残っていなければ、後からレビューも再利用もできません。
Codatum の Notebook は、SQL、チャート、Markdown、コメント、Agent とのやり取りを、ひとつの分析文書として同じ場所に残せる機能です。Agent が初期調査や SQL 生成を進め、人間がその計画や結果を確認し、必要に応じて修正します。最終的な数字だけでなく、分析の途中経過と判断が Notebook に残ります。
また、Agent が参照する文脈を整えることも重要です。データの意味をまとめた Catalog、分析の前提を渡す AI Profile、Notebook に蓄積された過去の分析、必要に応じて用意する .agent のような文脈は、Agent が毎回ゼロから推測する範囲を減らします。ただし、それは「Agent にすべて任せる」ためだけのものではありません。むしろ、人間が確認できる形で Agent を働かせるための土台です。
DAB から読み取れるのは、Data Agent がまだ未完成だということ以上に、Data Agent をどの単位で設計すべきかという話だと思います。SQL 生成器としてではなく、問い、計画、実装、検証をまたぐ分析システムとして設計していく必要があります。そう考えると、SQL が動いたかどうかよりも、分析の過程を後から確かめられるかどうかが効いてきます。
おわりに
38% という数字を悲観するためだけに読むと、Data Agent がどこで失敗しているのかを見落としてしまいます。正しいデータを選ぶだけでなく、正しい計算手順を組み、正しく実装し、結果を検証し、人間がレビューできる形で残す必要があります。
AI にデータ分析を任せるといっても、人間が分析から完全に消えるわけではなく、見るべき場所が変わっていくのだと思います。SQL を 1 行ずつ書く時間は減っても、その分、問いの立て方や計画の妥当性、検証の節目、最終的な意思決定に時間を使うようになります。
Data Agent の実務導入は、モデルの精度競争だけでは決まりません。SQL が動いたあとに、その分析を疑い、確かめ、チームで直せる形にできるかが、これからの分かれ目になると感じています。
参考文献
Can AI Agents Answer Your Data Questions? A Benchmark for Data Agents | Ruiying Ma, Shreya Shankar, Ruiqi Chen, Yiming Lin, Sepanta Zeighami, Rajoshi Ghosh, Abhinav Gupta, Anushrut Gupta, Tanmai Gopal, Aditya G. Parameswaran, 2026
DAB: Data Agent Benchmark | UC Berkeley EPIC Data Lab / Hasura PromptQL
ucbepic/DataAgentBench | GitHub
The Data Agent Benchmark | PromptQL