Contents
この記事のポイント
AIをデータ基盤につないでも、それだけでは正確な分析はできません。メタデータ整備の優先順位は、現場の分析ユースケースの蓄積から決まります。本記事では、AIが育つデータ活用の好循環の各ステップで起きがちな課題と解決策、そしてCodatumがどう解いているかを詳しく解説します。
AIをデータ基盤につないだだけでは、なぜうまくいかないのか
ChatGPTをデータベースにつないで「売上分析して」と言えば、もう分析は終わり——2026年3月現在、AIはまだそこまでは到達していません。
私たちCODATUMは、BIツールを開発・提供する中で、実際にChatGPTやClaudeをデータウェアハウスにつないで試してきました。技術的にはもう普通にできます。つないで、「この売上テーブルで月次推移を出して」と聞くと、ちゃんとSQLが返ってきて、グラフも出ます。「できた」と思うわけです。
でも、よく見ると全然違うテーブルを参照していたりします。売上の定義が社内のルールと違う集計になっていたり、除外すべきテストデータが混ざっていたり。AIはコードを書く力はあるけど、「この会社ではこのテーブルをこう使う」「この数字はこういう意味」「このデータには注意が必要」といった、組織に暗黙的に溜まっている文脈を持っていません。だから間違えます。
最初は「メタデータをちゃんと整備すればAIの精度は上がるはず」と考えていました。それ自体は正しいのですが、じゃあ何のメタデータを、どこから整備するのか。全テーブル・全カラムの説明を書くのは現実的ではありません。
この問いに向き合う中で私たちが気づいたのは、整備の優先順位は、現場の分析ユースケースから決まるということでした。現場の人たちがデータに触れて、AIと一緒に分析を試みて、「これはできた」「これはデータが足りなくてできなかった」というユースケースが溜まっていく。そこから「何を優先的に整備すべきか」が見えてきます。整備が進めばAIの精度が上がり、さらに多くの人がデータを使えるようになります。
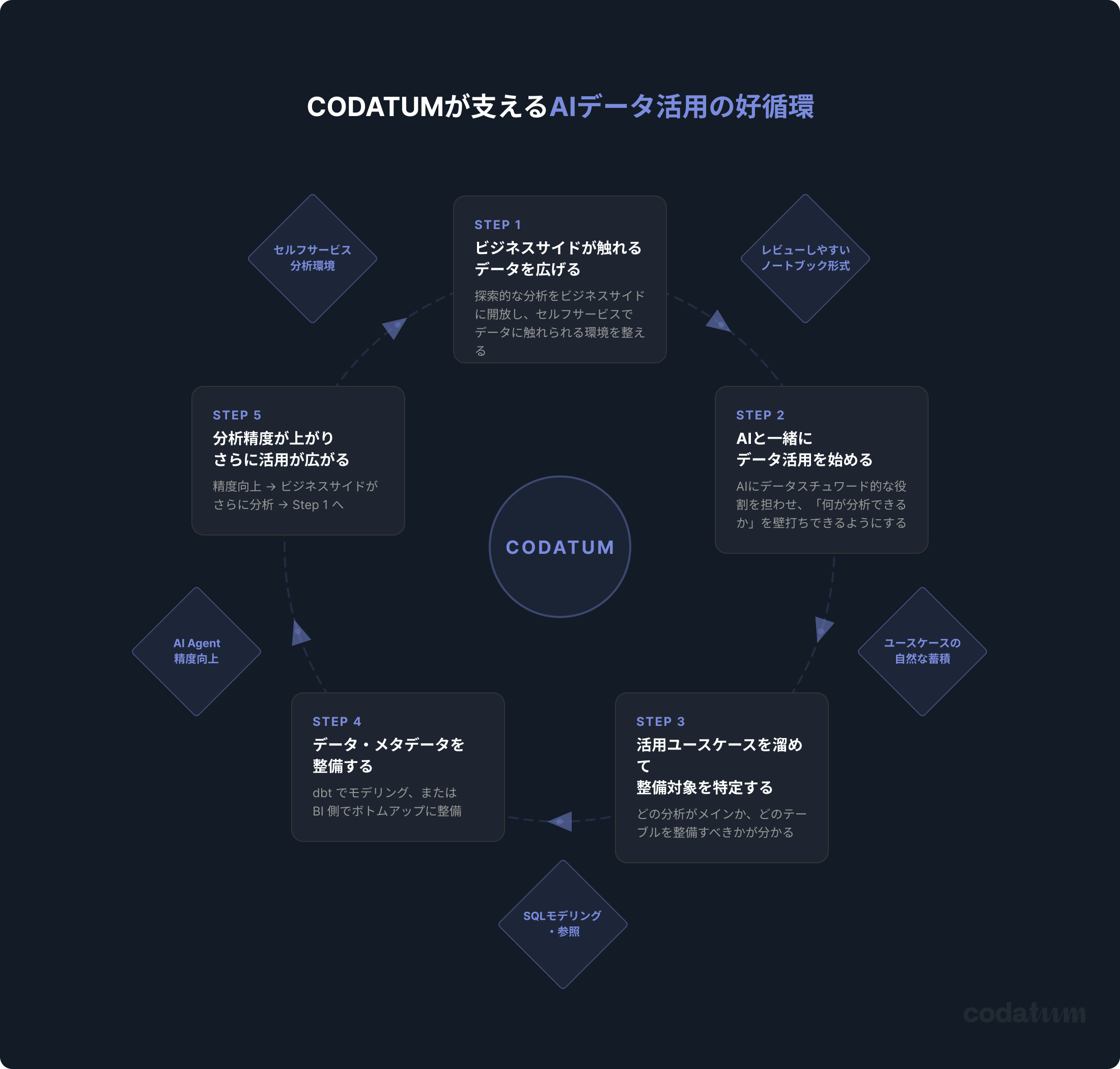
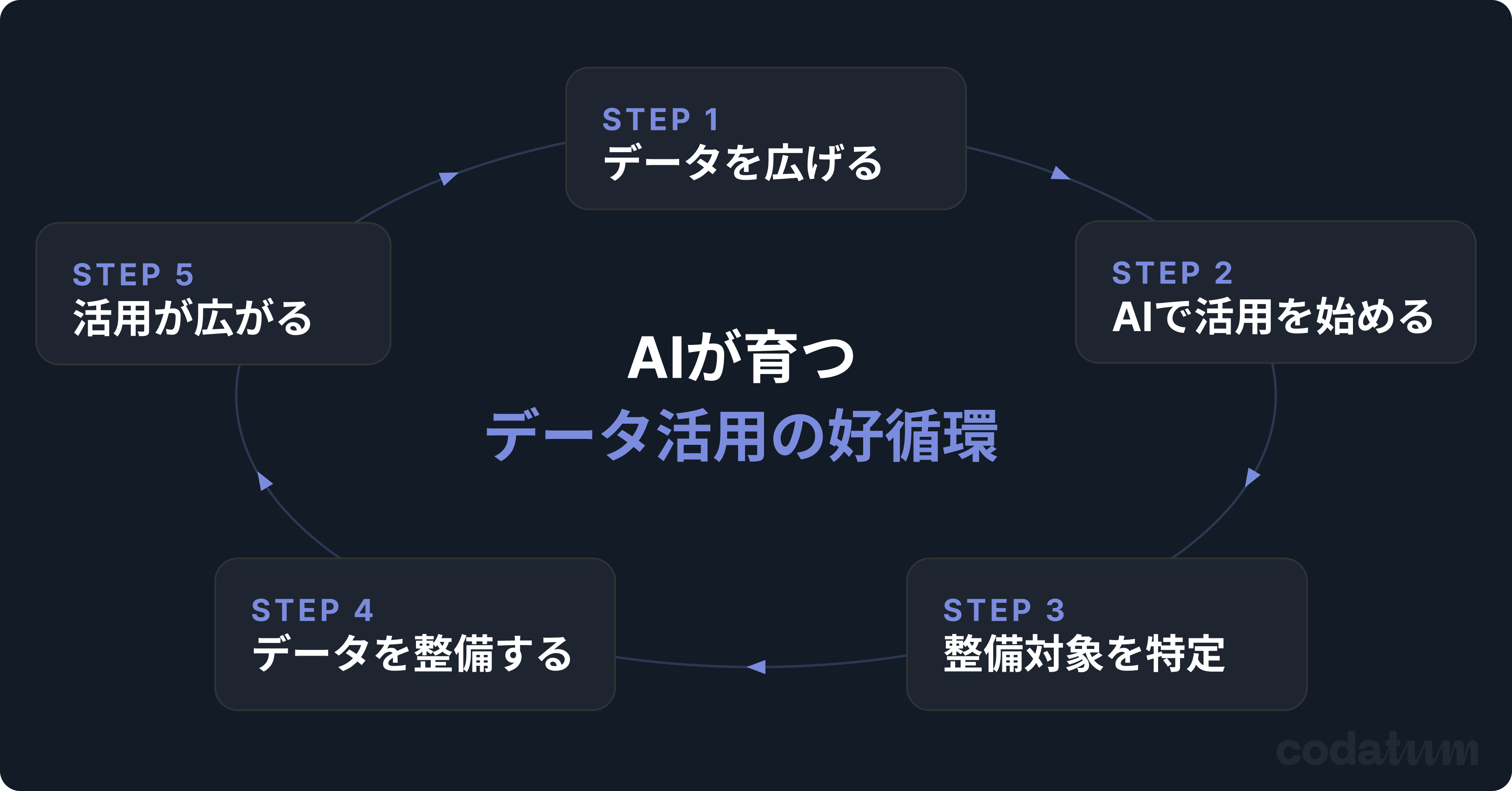
私たちはこのサイクルを「AIが育つデータ活用の好循環」と呼んでいます。本記事では、その各ステップで現実に起きがちな課題と解決策、そしてCodatumがどう解いているかを詳しく解説します。
AIが育つデータ活用の好循環:5つのステップ
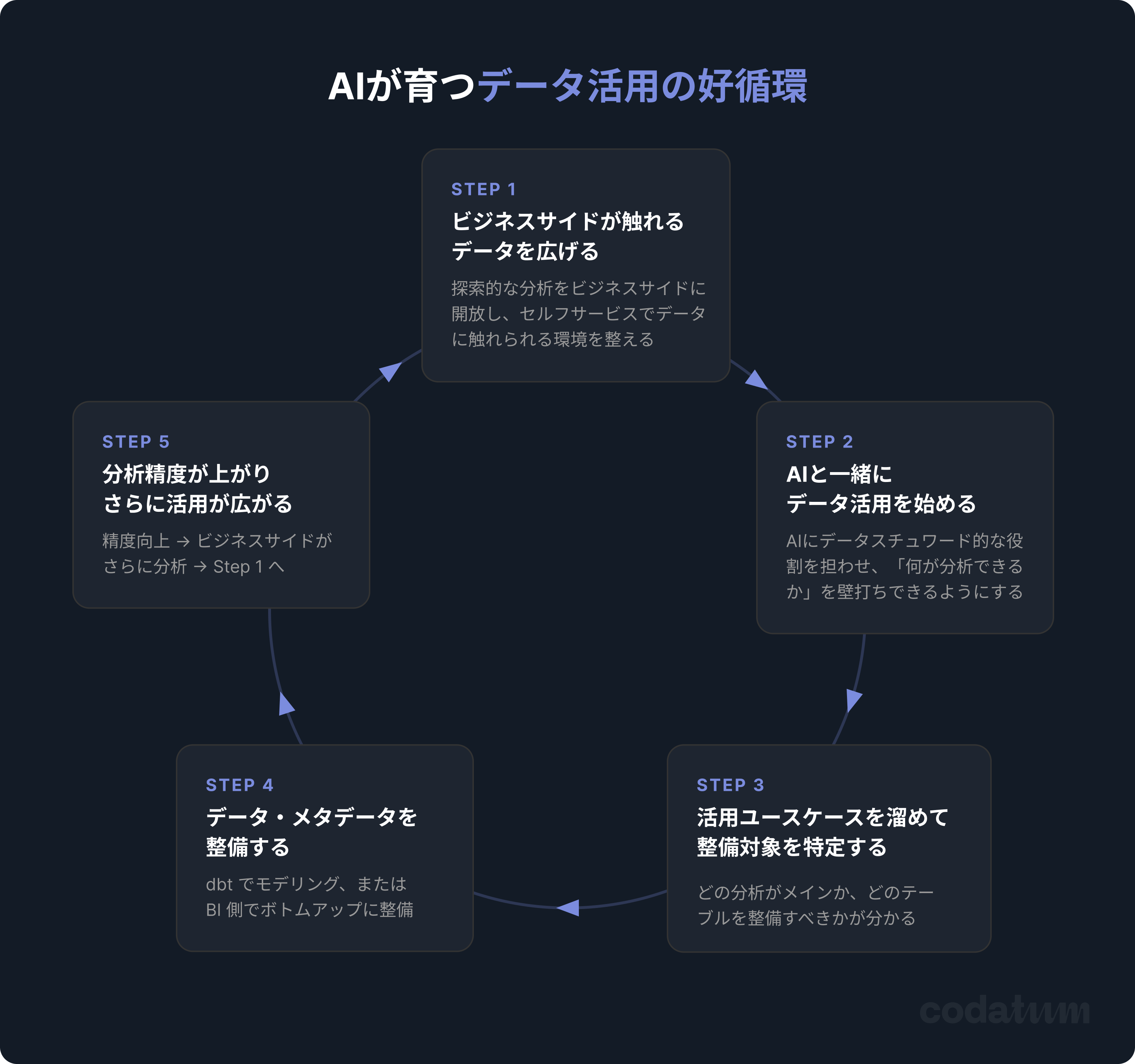
Step 1|現場の人たちが触れるデータを広げる
「データ活用をしよう」と言いながら、現場がデータに触れる機会は閲覧専用のダッシュボードのみ、という組織は少なくありません。これでは分析ユースケース自体が生まれません。まずは探索的な分析を現場に開放することが、好循環の出発点になると考えています。
よくある課題
分析環境がそもそも提供されていない
— 多くの組織では、現場のメンバーが深く・広く分析できる環境が用意されておらず、分析ユースケース自体が生まれてこない
データ閲覧権限の問題
— PII等のセンシティブデータを含む基盤に接続する場合、適切な権限設計と運用が必要になる
レビュー体制の不在
— ダッシュボードや分析クエリはコピーされて増殖する。間違った分析の増殖を止められるレビュー体制がないと、分析環境を開放しづらい
うまくいくパターン
現場がセルフサービスで分析できる環境を用意する
レビュー体制を仕組みとして作っておく。間違えそうなときに検出して、別の人が確認できるようにしておく
「絶対に間違えてはいけない分析」はわかる人がやるべき。ここで言っているのはそれ以外の探索的な分析の話
Codatumのアプローチ
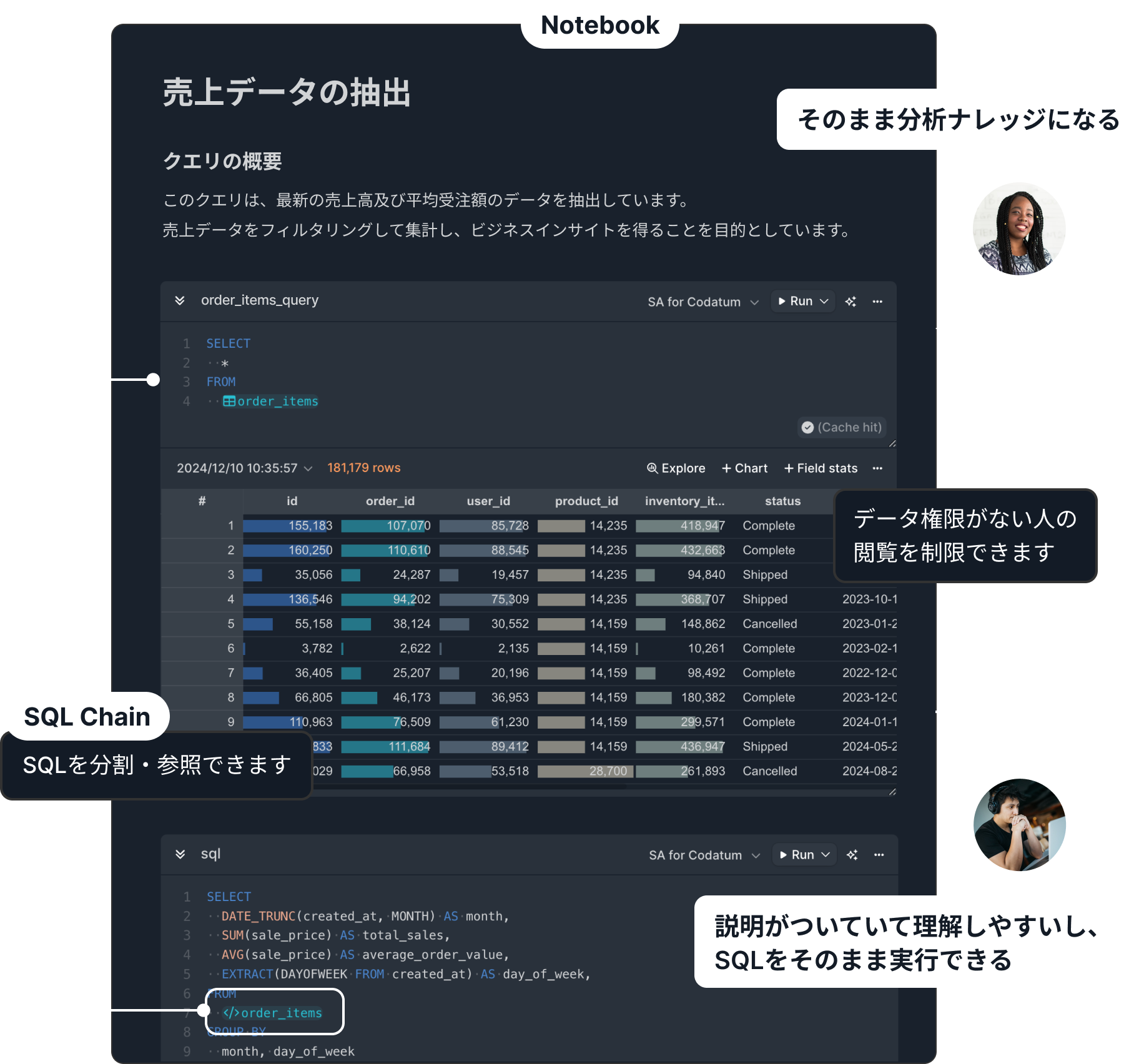
実行過程が全て残るノートブック形式×SQLで書かれているため、何をどう考えて分析したかをレビュアーが追いやすくなっています。現場のメンバーが分析を間違えても、レビューで気づける体制を作りやすくなっています。
Step 2|AIと一緒にデータ活用を始める
データを開放しただけでは、現場の人たちは実際にはデータを使い始めません。テーブルやカラムを見ても、自分の業務とどう紐づくかが分からないからです。この壁を越えるのがAIの役割です。
よくある課題
データ分析リテラシーの壁
— 現場のメンバーはテーブルやカラムを見ても、自分の業務・課題と紐づけることが難しい。「このデータで何が分析できるのか」「自分の業務のどの部分を数字で語れるようになるのか」がわからない
社内データに関する知識の壁
— どのテーブルがどう使えるか、どのデータが信頼できるかといった、社内固有のデータの使い方に関する知識が現場にはない
うまくいくパターン
AIに「データスチュワード」——つまり、社内のデータの意味や使い方を案内してくれる存在——としての役割を担わせる。現場のメンバーが自分の業務をAIに伝えて、「どんな分析ができるか」「自分の業務のどの部分を数字で語れるようになるか」を壁打ちする
「今あるデータでできる範囲で分析を始める」という進め方を、AIが現場と一緒に行う。データがあるかどうかを調べ、あるデータでできる分析を提案し、実際に分析を進める。曖昧な利用ユースケースを吸収できるAI Agentであることが大事
まだ解けない分析ユースケースが溜まること自体が、次のStep 3で整備対象を特定するためのインプットになる
Codatumのアプローチ
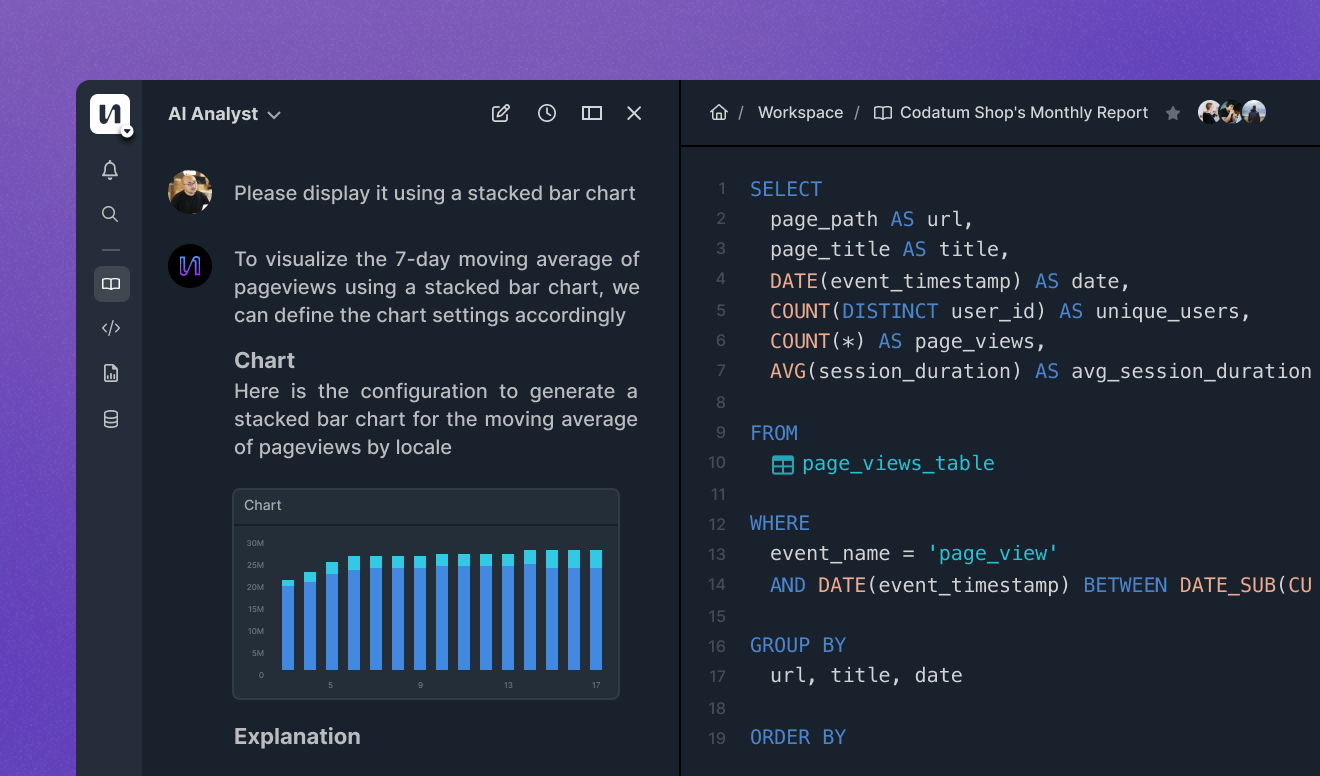
CodatumのAI Agentはエージェンティックに振る舞います。テーブルを自分で見つけに行き、中身を調べ、ユーザーのニーズに合わせて柔軟に分析を組み立てることができます。これにより、現場のメンバーが「自分の業務でどんな分析ができるか」をAIに壁打ちするデータスチュワード的な使い方が可能になります。
これは、あらかじめ決められた手順を実行するだけのAIワークフロー型のアプローチとは異なります。ワークフロー型では「ただ分析を実行する」だけになり、ユーザーの業務理解に基づいた分析提案やデータスチュワード的な伴走はできません。エージェンティックな振る舞いによって、対応できる幅が大きく広がります。今回のCodatumリリースはまさにこのAI Agentのリリースであり、この柔軟さが核になっています。
また、AI Agentとのやりとりを通じて「まだ解けていない分析ユースケース」も自然と集まります。ユーザーがAIに分析を依頼した結果、データが足りない・テーブルが整備されていないといったケースが可視化され、これがStep 3の整備対象を特定するインプットになります。Codatumではこの「まだ解けていないユースケース」をAI Agentを通じて収集する仕組みを構築していきます。
Step 3|活用ユースケースを溜めて、整備対象を特定する
AIと一緒に分析を始めるとユースケースが溜まってきますが、同時に間違った分析やデータが足りなくて解けないケースも出てきます。全てを整備するのは現実的ではないので、何を優先的に整備するかの判断が必要になります。
よくある課題
トップダウンアプローチの負荷
— 人間が明示的にレビュー依頼・優先順位を決めるやり方は確実だが、運用負荷が高くスケールしづらい
ボトムアップアプローチの困難さ
— 閲覧数・実行数などから利用ベースで自動集計してランキングしたいが、BIのリソースIDとDWHのクエリログが紐づいていないため「どのダッシュボードからよくテーブルを叩いているか」といった逆引きが難しい
うまくいくパターン
分析ユースケースが楽に溜まり、後から振り返りやすく、まとめやすい体制とツールを事前に構築しておく。探索的な分析は個人のローカル環境に閉じがちで、社内に共有されず、後から「どんな分析ニーズがあるのか」を把握しにくい
BI側で「どの分析がよく使われているか」を実績ベースで把握できるようにする(ボトムアップ)
加えて人間が明示的にレビュー・優先順位を指定できる導線も残す(トップダウン)
Codatumのアプローチ
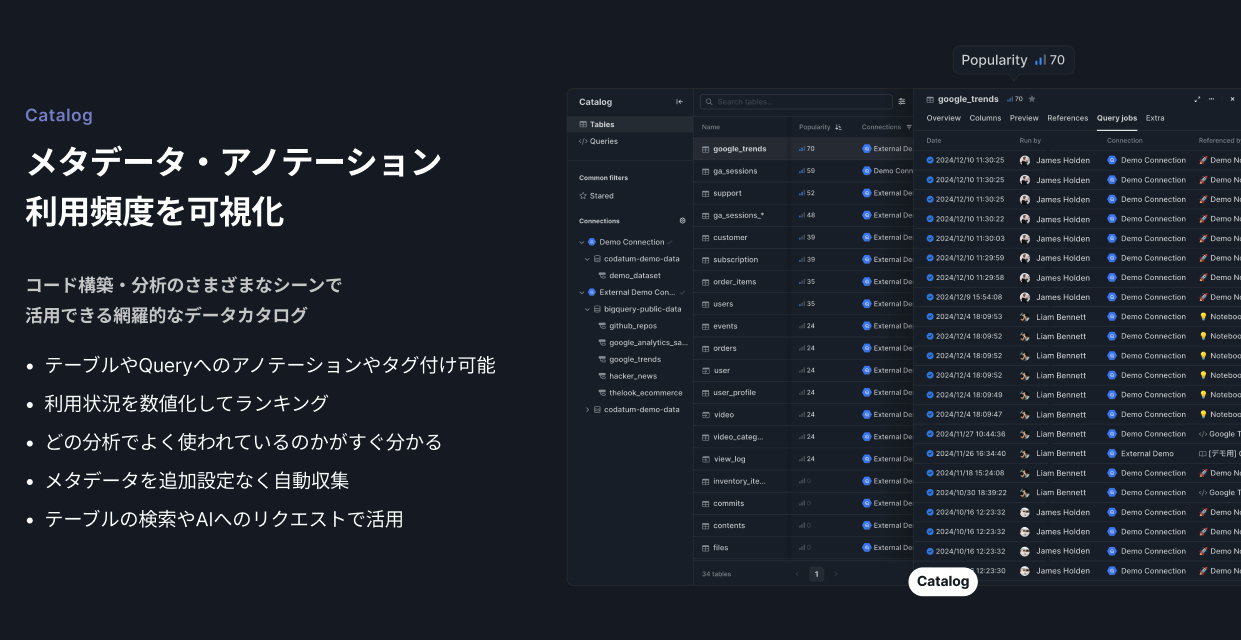
Codatumで分析を行うと、それがそのまま活用ユースケースとして記録されます。探索的な分析も社内に共有された状態で残るため、後から「どんな分析ニーズがあるのか」を把握しやすくなっています。アクティブなノートブック・よく見られているノートブックのランキングで、どんな分析ニーズが多いかが実績から分かります。ノートブックの内容はSQLで書かれているため、AIに渡してさらに深く分析傾向を振り返ることもできます。
Step 4|データ・メタデータを整備する
整備対象が決まったら、実際にデータとメタデータを整備します。ただし、全ての組織に専任のデータ基盤チームがいるわけではありません。
よくある課題
専門知識とリソースの問題
— 正攻法はDWH側でdbt等のデータモデリングツールを使った整備だが、専任の担当者や専門知識が必要であり、全ての組織にそのリソースがあるわけではない
チーム分離によるリードタイムの長期化
— データ基盤チームとBIを触るチームが分かれている場合、整備のリードタイムが長くなりがち
うまくいくパターン
dbtなどのデータモデリングツールを扱える人・ナレッジが組織にあるなら、そちらをAIと共に整備する
チームが分かれている場合や専任がいない場合は、BI側でまずボトムアップにモデリングを始める。よく使われるSQLを検出して共通化し、メタデータ(説明・使い方)や分析サンプルを作成していく
BI側で固まってきたものを、段階的にDWH側に書き戻す形が効率的。BI側での探索的な整備 → DWH側での本格管理、という段階的なアプローチ
Codatumのアプローチ
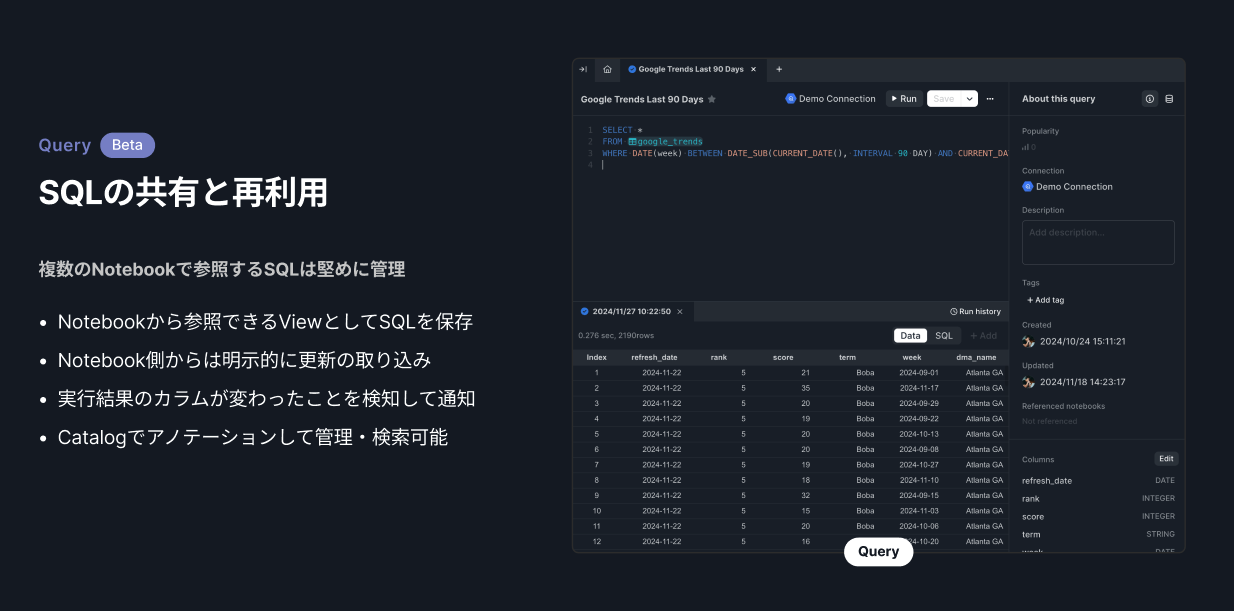
SQLのモデリング・参照機能で、BI側からのボトムアップ整備をサポートしています。一つのSQLを整理しておくと、複数の分析ノートブックからそのSQLを参照できます。よく使われるクエリを共通化し、メタデータや分析サンプルを付与していく運用が可能です。
Step 5|分析精度が上がり、さらに活用が広がる
データとメタデータが整備されると、AIが精度高く分析できるテーブルの対象範囲が広がります。その結果、これまで対応できていなかった分析ユースケースにもAIが対応できるようになります。新たな分析に対応できるようになることで、さらにデータ活用が広がります。
よくある課題
活用の想像力の壁
— データとメタデータが整備されても、それを使って何ができるか・どんな分析が可能になったかは、分析に精通していないと思いつけないことが多い
キャッチアップの仕組みの不在
— 新しく整備されたテーブルやメタデータを利用者がキャッチアップできる仕組みがないと、整備したのに使われない
うまくいくパターン
データとメタデータの整備には、元々対応したかった分析ユースケースがあるはず。それを分析サンプルとしてBI側に作成・共有しておくと、使う側にもAIにも信頼できる参照先になる
データスチュワードAIにとっても、分析サンプルがあることで現場への紹介がより具体的になる
分析する側は「どんな分析ができそうか」をユースケースレベルで考えやすくなる
これまで対応できていなかった分析ユースケースにもAIが対応できるようになり、データ活用がさらに広がることで、Step 1へのループが回ります。
Codatumのアプローチ
AI Agentが整備済みのメタデータと分析サンプルを自動活用し、AIが精度高く分析できるテーブルの対象範囲を広げます。また、分析サンプルがあることでデータスチュワードAIとしての紹介が具体的になり、現場のメンバーが新たな分析に取り組みやすくなります。精度が上がった分析結果が新たな活用ユースケースを生み、好循環がさらに加速します。