
Contents
ウェブアプリケーションの大きな利点の一つが、複数人による「状態の共有」にあります。オフラインの物理的何かや、ローカルで動作するDesktop Appは個人で使うことを想定していますが、ウェブアプリケーションの対象は、個人の生産性だけではなく、チームや組織の生産性にあります。その時に重要なのが「状態の共有」です。
一般的には、 あるユーザーAが「保存」ボタンを押して保存し、少し遅れて別のユーザーBが保存したら、ユーザーBの保存で単純に上書きしてしまい、ユーザーAの「保存」が無かったことになるか、それとも遅れた方 (ユーザーB) の保存を棄却するか、どちらかのポリシーを取ると思います。そして取り入れた修正内容を両方に最新の情報としてPushします。
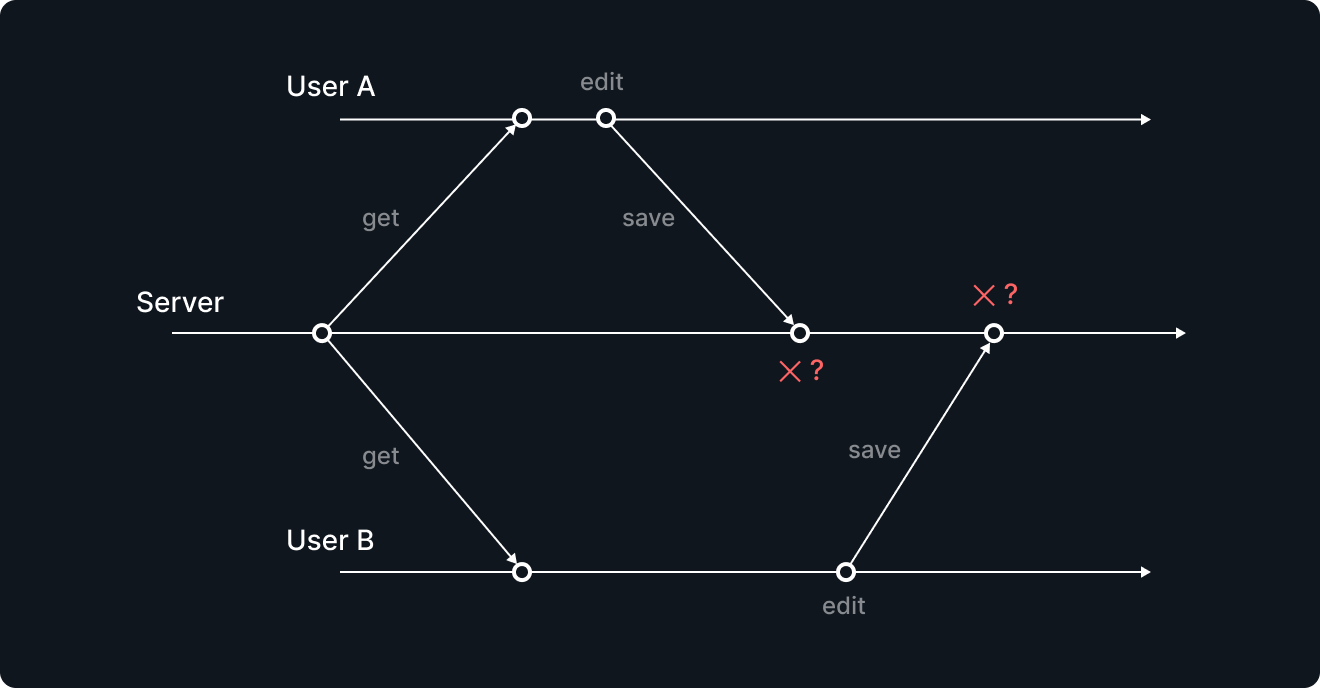
しかし、編集対象が大きい場合には、ユーザーAの部分修正とユーザーBの部分修正をどちらも取り入れたいケースがあります。
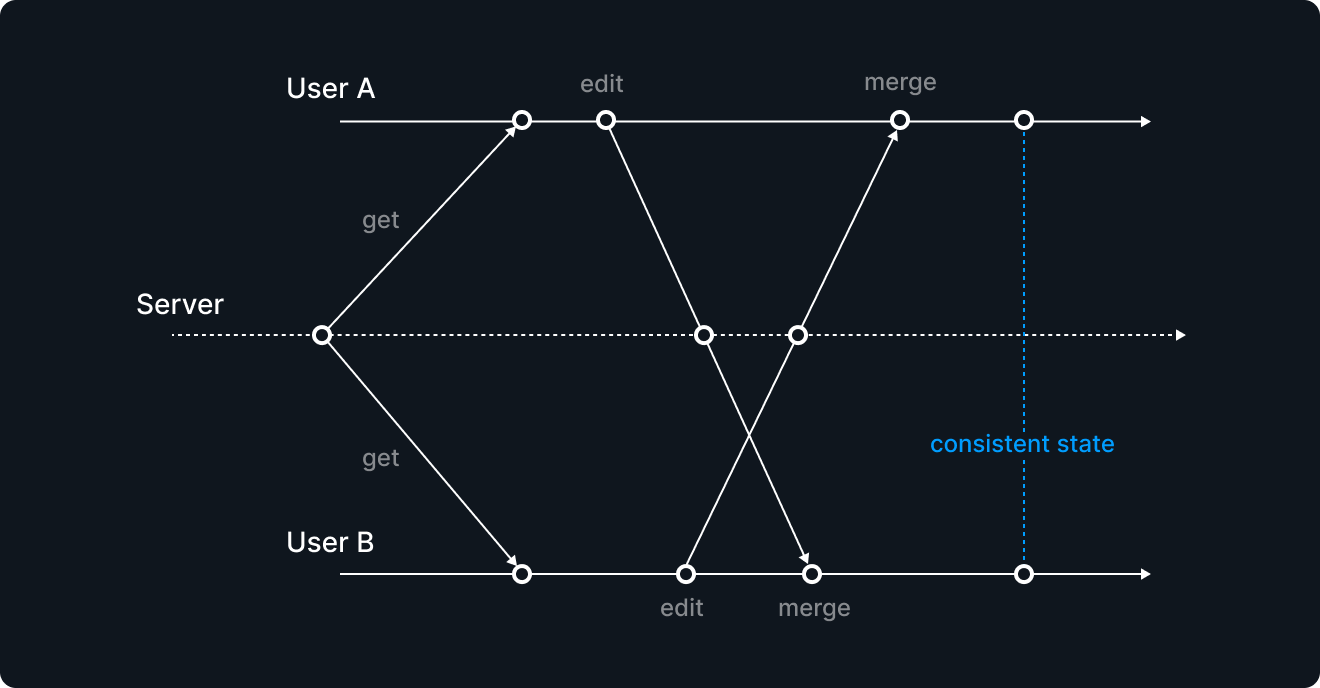
CRDTはそのような時に使えるデータ構造やアルゴリズムの総称であり、YjsはCRDTの有名な実装です。CRDTを使うと複数のユーザーが同時に状態に修正を加えても(結果)整合性を保つことができ、最新の内容を双方が知ることができます。
CodatumにおけるYjs
Codatumでは「共同作業」を重視しています。そのため多くの状態をリアルタイムに共有します。全てではありませんが、適所でYjsを使い、状態の共有を行っています。Notebookのような文書の共有はYjsのメインターゲットですが、それだけではなく、GridにおけるTileの位置やサイズなども共有しています。
単純に利用する分には、詳しく知る必要はありませんが、利用すべき場所の判断、パフォーマンスチューニング、debuggingなどなど、内部を理解しておくと便利です。
一般的なWebアプリケーションでの利用
HocuspocusのようなYjsのバックエンドを用いると、簡単に「状態の共有」「共同編集」「最新状態のPush」ができます。後述しますが、Documentに対する「共同編集」だけではなく、短いTextや単なるMapやArrayのようなデータもYjsは賢く扱います。また個人利用であっても別デバイス間での状態共有にも使えます。全ての、とまではいきませんが、多くのウェブアプリケーションにとって状態管理の選定対象にして良いものに感じます。
Yjsを利用しているプロダクト例
Yjs (若しくはそのRust実装であるyrs) はさまざまなツールで利用されています。有名なものでは、Gitbook, Evernote, Nimbus Note, AWS SageMaker, linear, Multi.app, Eclipse Theia, Hyperquery などがあります。その多くでは、文書の共同編集に利用していますが、Spreadsheetや、Drawingに利用しているものもあるようです。
YATA (Yet Another Transformation Approach)
参考文献
(*1) Near Real-Time Peer-to-Peer Shared Editing on Extensible Data Types: ACM Proceedings of the 19th International Conference on Supporting Group Work (2016)
Yjsの実装の元となっているCRDTのアルゴリズムは2016年の上記Paper (*1) で紹介されています。YATAは次のような特徴を持っています。
結果整合性の保証
複数のクライアントが同じドキュメントを同時に編集しても、すべてのクライアントが同じ最終状態に到達します。
オフライン編集のサポート
クライアントがオフライン時に行った編集も、オンラインに戻った際に正しく統合されます。
シンプルなデータ構造とアルゴリズム
基本データ構造は双方向リンクリストで、競合した場合においてもユーザーの意図をなるべく保ちつつ、非常にシンプルな競合解消のアルゴリズムを持ちます。
多様なデータ型への適用可能性
テキストだけでなく、リスト、マップ、XMLなどの構造データなど、さまざまなデータ型を表現できる柔軟性があります。
スケーラビリティと低帯域幅対応
更新操作は非常にコンパクトで、低帯域幅の環境でも効率的に動作します。
このようなCRDTに要求される機能を持ちつつ、考え方やデータ構造、アルゴリズムは非常にシンプルです。
データ構造
YATAのコアとなるデータ構造は、線形データ型(テキストや配列)を表現するための双方向リンクリストです。このリンクリストのNode (Operation) は基本的には、挿入そのものです。テキストや配列順に並ぶことが期待されています。
Operationは次のようなプロパティを持っています:
Operation {
id: { // Lamport Timestamp
clientId: string,
clock: number,
},
origin: Operation, // 要素が挿入された際の左の参照
left: Operation, // 要素が挿入された際の左の参照
right: Operation, // 要素が挿入された際の右の参照
isDeleted: boolean, // 削除されたかどうかを示すフラグ
content: any, // 要素の内容(例:文字、Map、他のデータ型)
idx: number // linked list内でのindex
}アルゴリズム
操作は挿入と削除のみです。競合が発生していない時、YATAでは挿入も削除も非常に簡単です。挿入は、originの右側にOperationを入れるだけで、削除はisDeletedのフラグをtrueにするだけです。また、削除はフラグを変えるだけなので、削除同士では競合しないし、削除と挿入も競合しません。競合しうるのは、挿入同士になります。
ここでは同じ位置に挿入された複数のOperationの競合回避について疑似コードを用いて説明します。
// i: Inserting operation
// ops: conflicting operations which exist between i.left and i.right
// return: Inserting index
function insert(i: Operation, ops: Operation[]): number {
let index = ops[0]?.idx || 0;
for (o in ops) {
if (
// Rule1
(o.idx < i.origin.idx || i.origin.idx <= o.origin.idx)
&&
// Rule3
(o.origin.idx != i.origin.idx || o.id < i.id)
) {
index = o.idx + 1
} else {
if (i.origin.idx > o.origin.idx)
break;
}
}
return index;
}insert関数は、あるOperation iと、i.leftからi.rightの間にあるops (挿入が競合したOperation) を引数にとり、挿入すべきindexを返す関数です。
opsを頭からscanし、あるルールを満たしている最後のindexを返します。そのルールを下の図に示します。
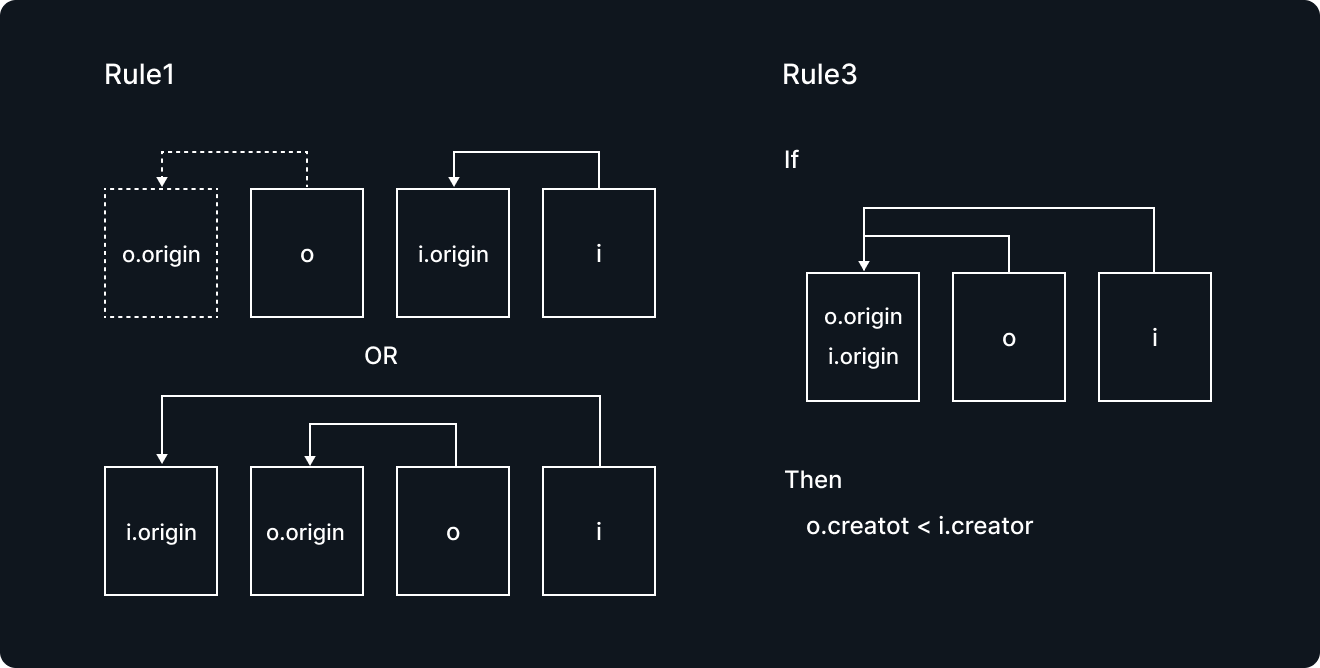
Rule1はNo line crossingと呼ばれるもので、originがcrossしない、と言うものです。これが意図(例: 同じクライアントが連続的に書いたものを連続的に並べる)をなるべく保持しようとしているルールでもあります。また、Rule3については、先に書かれたものがOriginに近くなるルールです。(Rule2については数学的な準備のためのものなので割愛しています。)
驚きなのは、このようなシンプルなデータ構造とたった2つのシンプルなルールによる競合回避のアルゴリズムで、Operationが来る順番がまちまちでも、全てのクライアントで同じ形に収束することが保証されている点です。これの証明に関しては元論文に当たってください。
その他のデータ型
またYATAの面白い、そして美しいところは、この線形データのデータ構造を使って、複雑なデータ型であっても同じように表現できることです。まずTextとArrayは上記で説明した通りですが、同じリンクリストを使い、単純に右に追記するだけの操作を許し、値として一番右のOperationのみを取り出すデータ型を用意すると、置換をしていくデータ型を用意することができます。このデータ型をkeyごとに割り当てれば、Map型を表現することもできます。
これらを拡張すれば、XMLのようなデータ型も、attributeをMap型で、childrenをArray
Yjsでの最適化
参考文献
(*2) Yjs Internals
(*3) Are CRDTs suitable for shared editing?
(*4) Deep dive into Yrs architecture
Yjsでは、元論文に対して各種の最適化が入っています。
元論文では、一文字一文字をObjectにするケースで書かれているので、特にメモリ使用のオーバーヘッドが大きくなるように見えます。しかし (*3) ではそれに対して、Yjsでは実は、単一文字ではなく、連続した複数文字をcontentに入れることで、現実的なユースケースにおいては大きな問題にならないこと、が言及されています。
また、そのような複数文字を一つのobjectで表現した場合、その一部の文字列が削除されたり、間に挿入があった場合に、objectをsplitする必要があります。また、連続したものをsquashしてまとめ上げる必要があることも容易に想像できます。Yjsのrust移植版であるyrsの内部構造について説明している (*4) においては図付きでこのsplit/squashがどのように行われているか、を説明しています。
これ以外にも (*2) において、originRighの導入や、Transactionの導入などによる最適化などについても言及されています。
まとめ
この記事では、ウェブアプリケーションにおける複数人の生産性を向上させるための、「状態の共有・共同編集」の1アプローチとして、CRDTの有名な実装である、Yjsの内部構造について説明しました。
Yjsが参照しているYATAは、シンプルなデータ構造とシンプルな競合回避アルゴリズムで、分散環境でも結果整合性を保てることと、それをツリー構造にすることで、XMLのような複雑な構造的データ型も表現できる、非常に強力なCRDTであることを説明しました。また、YjsではYATAのPerformance的な課題に対して、split/squashのような独自の機構を入れることで現実問題に対処していることを説明しました。
Codatumはこのような強力なYjsの力も借りて、データ分析におけるチームや組織の共同作業を活発化させるような機能を開発しています。ぜひ利用してみてください。また、開発等に興味がある方もご連絡ください!